◉ Paligemma VLM from scratch#
Why??? Just to brush-up various concepts in building a simple VLM…
Will use google/paligemma-3b-pt-224 weights from huggingface
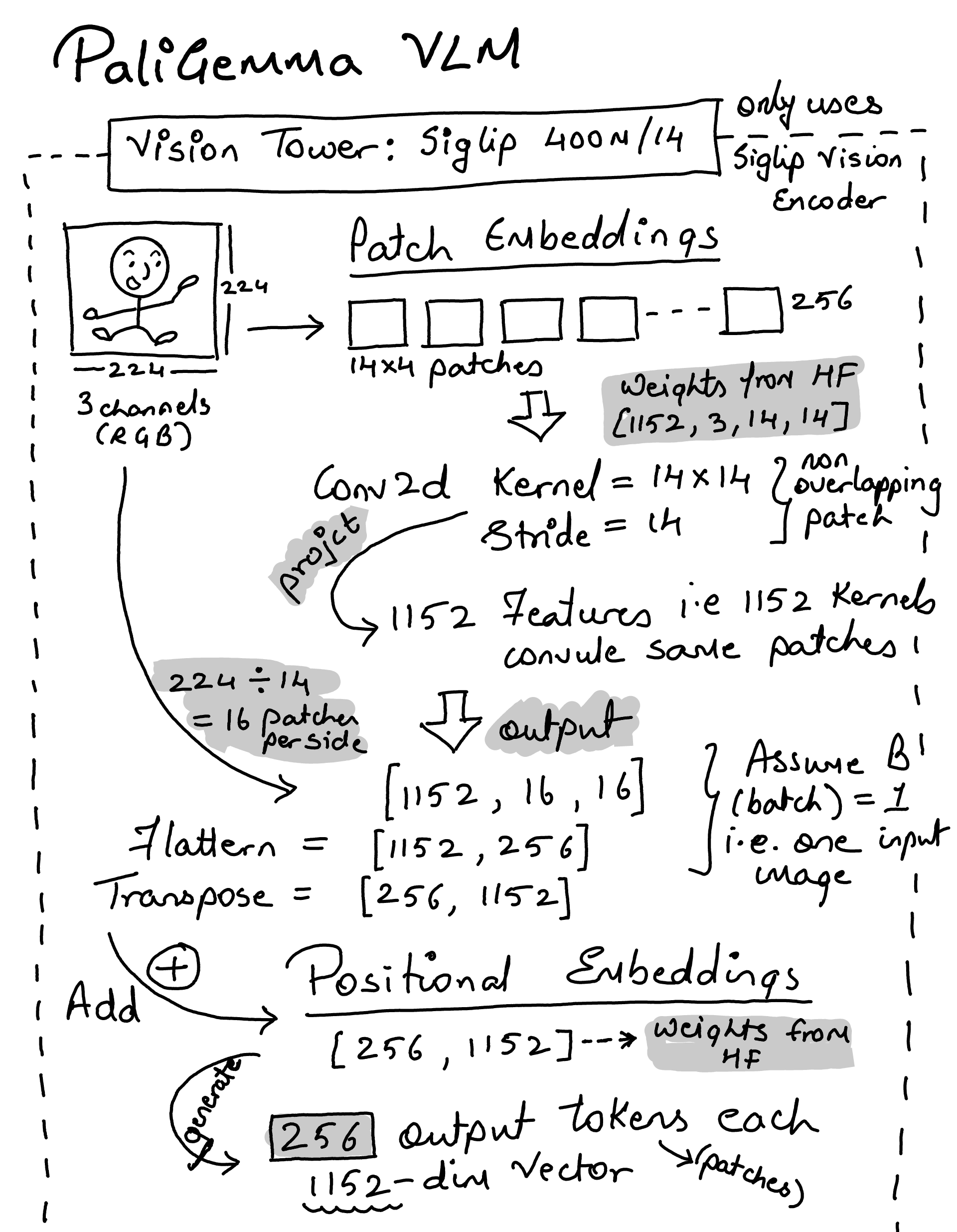
Vision Tower: SigLIP Vision Encoder 400M (14 patch size)
Multi-Model Projector (In: 1152 –> Out: 2048)
Gemma 2B as language model
import torch
import os
from utils import load_hf_model
model_path = os.path.expandvars("$HOME/code/models/paligemma-3b-pt-224")
device = "cpu"
if torch.cuda.is_available():
device = "cuda"
elif torch.backends.mps.is_available():
device = "mps"
print("Device in use: ", device)
model, tokenizer = load_hf_model(model_path, device)
model
/Users/n0man/Code/machine-learning/vlm-from-scratch/env/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Device in use: mps
PaliGemmaForConditionalGeneration(
(vision_tower): SiglipVisionModel(
(vision_model): SiglipVisionTransformer(
(embeddings): SiglipVisionEmbeddings(
(patch_embedding): Conv2d(3, 1152, kernel_size=(14, 14), stride=(14, 14), padding=valid)
(position_embedding): Embedding(256, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(self_attn): SiglipAttention(
(q_proj): Linear(in_features=1152, out_features=1152, bias=True)
(k_proj): Linear(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear(in_features=1152, out_features=1152, bias=True)
)
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
(multi_modal_projector): PaliGemmaMultiModalProjector(
(linear): Linear(in_features=1152, out_features=2048, bias=True)
)
(language_model): GemmaForCausalLM(
(model): GemmaModel(
(embed_tokens): Embedding(257216, 2048, padding_idx=0)
(layers): ModuleList(
(0-17): 18 x GemmaDecoderLayer(
(self_attn): GemmaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=256, bias=False)
(v_proj): Linear(in_features=2048, out_features=256, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
(mlp): GemmaMLP(
(gate_proj): Linear(in_features=2048, out_features=16384, bias=False)
(up_proj): Linear(in_features=2048, out_features=16384, bias=False)
(down_proj): Linear(in_features=16384, out_features=2048, bias=False)
)
(input_layernorm): GemmaRMSNorm()
(post_attention_layernorm): GemmaRMSNorm()
)
)
(norm): GemmaRMSNorm()
)
(lm_head): Linear(in_features=2048, out_features=257216, bias=False)
)
)
Note
throughout the notebook, will use class and parameters name same as HF Paligemma impelementation or safetensor dict so that when we load the model model.load_state_dict(tensors, strict=False) it will automatically load weights and bias to matching parameter names… e.g.
```
vision_tower.vision_model.embeddings.patch_embedding.weight
vision_tower.vision_model.embeddings.patch_embedding.bias
vision_tower.vision_model.embeddings.position_embedding.weight
vision_tower.vision_model.encoder.layers.0.self_attn.q_proj.weight
vision_tower.vision_model.encoder.layers.0.self_attn.q_proj.bias
...
language_model.model.embed_tokens.weight
language_model.lm_head.weight
```
strict=False means it won’t error if some keys don’t match
SiglipVisionConfig#
from typing import Optional, Tuple
import torch
import torch.nn as nn
class SiglipVisionConfig:
def __init__(
self,
hidden_size=1152,
intermediate_size=4304,
num_hidden_layers=27,
num_attention_heads=16,
num_channels=3,
image_size=224,
patch_size=14,
layer_norm_eps=1e-6,
attention_dropout=0.0,
num_image_tokens: int = 256,
**kwargs,
):
super().__init__()
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.num_channels = num_channels
self.patch_size = patch_size
self.image_size = image_size
self.attention_dropout = attention_dropout
self.layer_norm_eps = layer_norm_eps
self.num_image_tokens = num_image_tokens
Siglip Vision Embeddings#

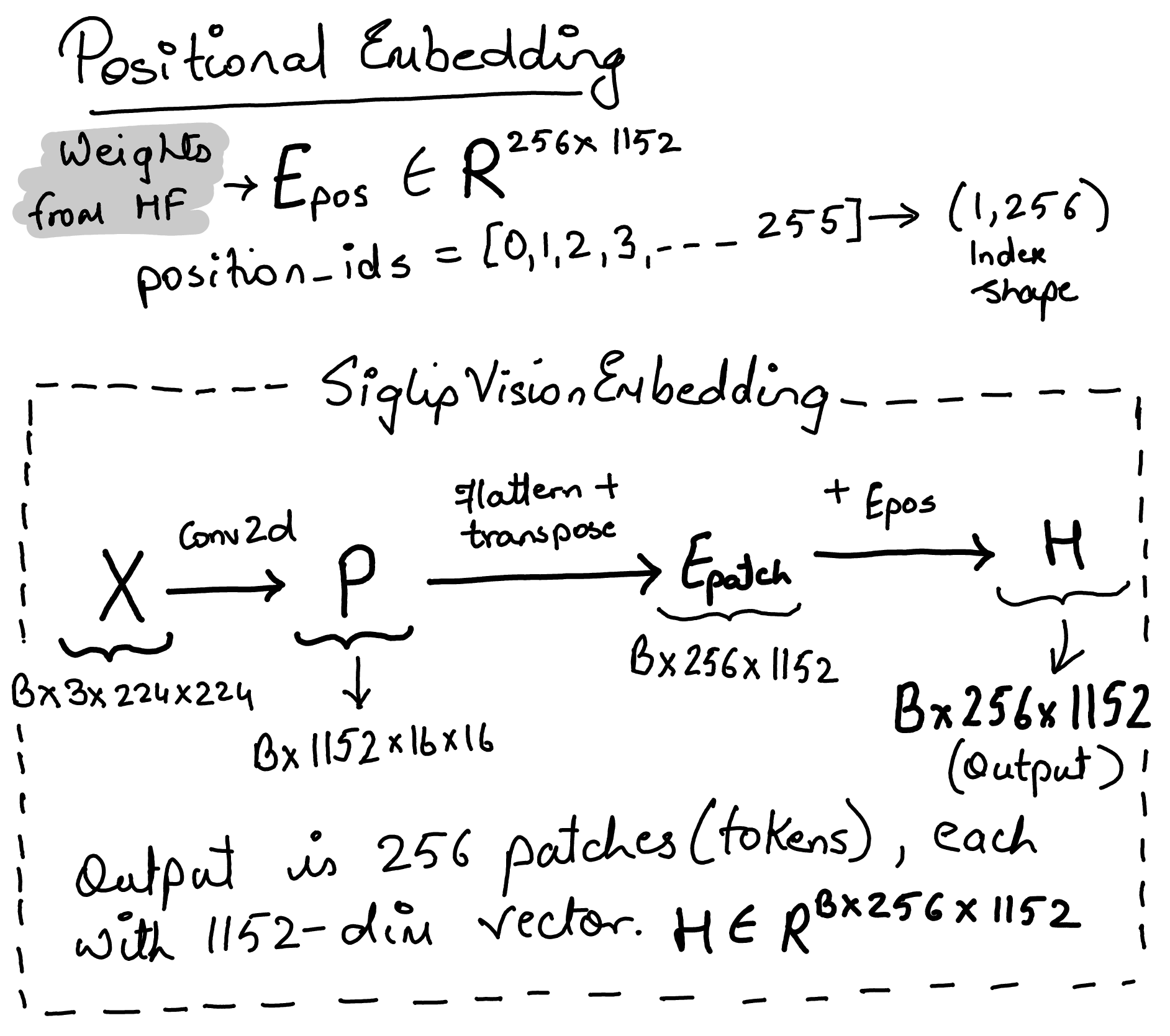
class SiglipVisionEmbeddings(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.image_size = config.image_size
self.patch_size = config.patch_size
self.patch_embedding = nn.Conv2d(
in_channels=config.num_channels,
out_channels=self.embed_dim,
kernel_size=self.patch_size,
stride=self.patch_size,
padding="valid", # no padding is added
)
# ** 2 because image and patch size are represented as single dim, but they are actually 2d i.e. the actual patch size is 16x16
self.num_patches = (self.image_size // self.patch_size) ** 2
self.num_positions = self.num_patches
self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
self.register_buffer(
"position_ids",
torch.arange(self.num_positions).expand((1, -1)),
persistent=False,
)
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
_, _, height, width = (
pixel_values.shape
) # [Batch_Size, Channels, Height, Width]
# Convolve the `patch_size` kernel over the image, with no overlapping patches since the stride is equal to the kernel size
# The output of the convolution will have shape [Batch_Size, Embed_Dim, Num_Patches_H, Num_Patches_W]
# where Num_Patches_H = height // patch_size and Num_Patches_W = width // patch_size
patch_embeds = self.patch_embedding(pixel_values)
# [Batch_Size, Embed_Dim, Num_Patches_H, Num_Patches_W] -> [Batch_Size, Embed_Dim, Num_Patches]
# where Num_Patches = Num_Patches_H * Num_Patches_W
embeddings = patch_embeds.flatten(2)
# [Batch_Size, Embed_Dim, Num_Patches] -> [Batch_Size, Num_Patches, Embed_Dim]
embeddings = embeddings.transpose(1, 2)
# Add position embeddings to each patch. Each positional encoding is a vector of size [Embed_Dim]
embeddings = embeddings + self.position_embedding(self.position_ids)
# [Batch_Size, Num_Patches, Embed_Dim]
return embeddings
Note
register_buffer registers position_ids as a non-parameter tensor on the module — it moves with the model to the correct device and is included in state_dict traversal, but is not a learnable parameter (no gradients). persistent=False means it won’t be saved in state_dict (it’s reconstructed from code).
The lookup self.position_embedding(self.position_ids) produces shape \((1, 256, 1152)\)
Using ConvNet in ViT#
difference between using ConvNet in CNN vs ViT
CNN |
ViT |
|
|---|---|---|
Purpose |
Hierarchical feature extraction through many conv layers |
One-shot patch tokenization. Single conv layer |
Kernel/stride |
Small kernels e.g. 3×3, stride 1-2, with overlap |
Large kernel e.g. 14x14, stride = kernel size, no overlap |
Depth |
Many conv2d layers stacked (feature hierarchy) |
Just one conv, then transformer layers take over |
Output |
Progressively downsampled feature maps → flatten → FC → class logits |
Sequence of patch embedding vectors → fed to transformer encoder |
So… a classification (CNN) ConvNet uses convolutions as its core computation (many layers, overlapping receptive fields, spatial hierarchies). In ViT, the Conv2d is just a tokenizer… a single efficient linear projection to turn image patches into embedding vectors for the transformer.
Siglip Multi Head Attention#
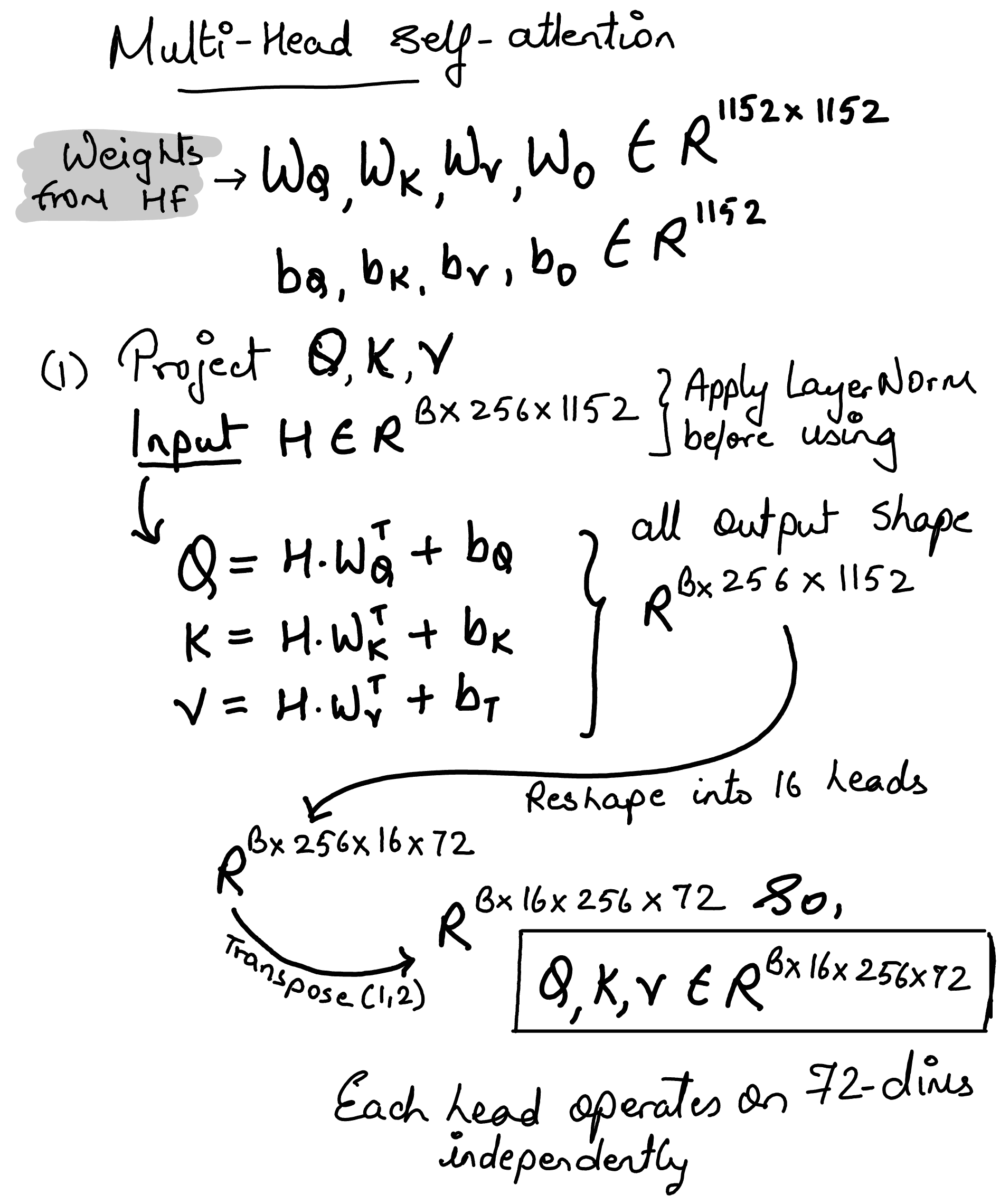


Note
calling self.q_proj(hidden_states) invokes nn.Linear.__call__, which internally calls forward, computing \(\mathbf{x}\mathbf{W}^\top + \mathbf{b}\).
Note
With attention_dropout=0.0, this is a no-op. The self.training flag ensures dropout is only active during training
class SiglipAttention(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.embed_dim // self.num_heads
self.scale = self.head_dim**-0.5 # Equivalent to 1 / sqrt(self.head_dim)
self.dropout = config.attention_dropout # not being used anywhere
self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
def forward(
self,
hidden_states: torch.Tensor,
) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
# hidden_states: [Batch_Size, Num_Patches, Embed_Dim]
batch_size, seq_len, _ = hidden_states.size()
# query_states: [Batch_Size, Num_Patches, Embed_Dim]
query_states = self.q_proj(hidden_states)
# key_states: [Batch_Size, Num_Patches, Embed_Dim]
key_states = self.k_proj(hidden_states)
# value_states: [Batch_Size, Num_Patches, Embed_Dim]
value_states = self.v_proj(hidden_states)
# view: [Batch_Size, Num_Heads, Num_Patches, Head_Dim]
# i.e. bread the dims into heads x heads_dims
query_states = query_states.view(
batch_size, seq_len, self.num_heads, self.head_dim
).transpose(1, 2)
key_states = key_states.view(
batch_size, seq_len, self.num_heads, self.head_dim
).transpose(1, 2)
value_states = value_states.view(
batch_size, seq_len, self.num_heads, self.head_dim
).transpose(1, 2)
# Calculate the attention using the formula Q * K^T / sqrt(d_k)
# attn_weights: [Batch_Size, Num_Heads, Num_Patches, Num_Patches]
attn_weights = (
torch.matmul(query_states, key_states.transpose(2, 3)) * self.scale
)
if attn_weights.size() != (batch_size, self.num_heads, seq_len, seq_len):
raise ValueError(
f"Attention weights should be of size {(batch_size, self.num_heads, seq_len, seq_len)}, but is"
f" {attn_weights.size()}"
)
# Apply the softmax row-wise. attn_weights: [Batch_Size, Num_Heads, Num_Patches, Num_Patches]
attn_weights = nn.functional.softmax(
attn_weights, dim=-1, dtype=torch.float32
).to(query_states.dtype)
# Apply dropout: used only during training, no effect during inference.
# attn_weights: [Batch_Size, Num_Heads, Num_Patches, Num_Patches]
attn_weights = nn.functional.dropout(
attn_weights, p=self.dropout, training=self.training
)
# Multiply the attention weights by the value states. attn_output: [Batch_Size, Num_Heads, Num_Patches, Head_Dim]
attn_output = torch.matmul(attn_weights, value_states)
if attn_output.size() != (batch_size, self.num_heads, seq_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(batch_size, self.num_heads, seq_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
# [Batch_Size, Num_Heads, Num_Patches, Head_Dim] -> [Batch_Size, Num_Patches, Num_Heads, Head_Dim]
attn_output = attn_output.transpose(1, 2).contiguous()
# [Batch_Size, Num_Patches, Num_Heads, Head_Dim] -> [Batch_Size, Num_Patches, Embed_Dim]
attn_output = attn_output.reshape(batch_size, seq_len, self.embed_dim)
# [Batch_Size, Num_Patches, Embed_Dim]
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights
Siglip Multi Layer Perceptron#
Position-wise feed-forward network… applied independently to each patch’s representation

class SiglipMLP(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.fc1(hidden_states)
hidden_states = nn.functional.gelu(hidden_states, approximate="tanh")
hidden_states = self.fc2(hidden_states)
return hidden_states
Siglip Encoder (27 x Transformer layers)#
Stack 27 transformer blocks sequentially… Each layer (block) contains self-attention + MLP, both with residual connections…
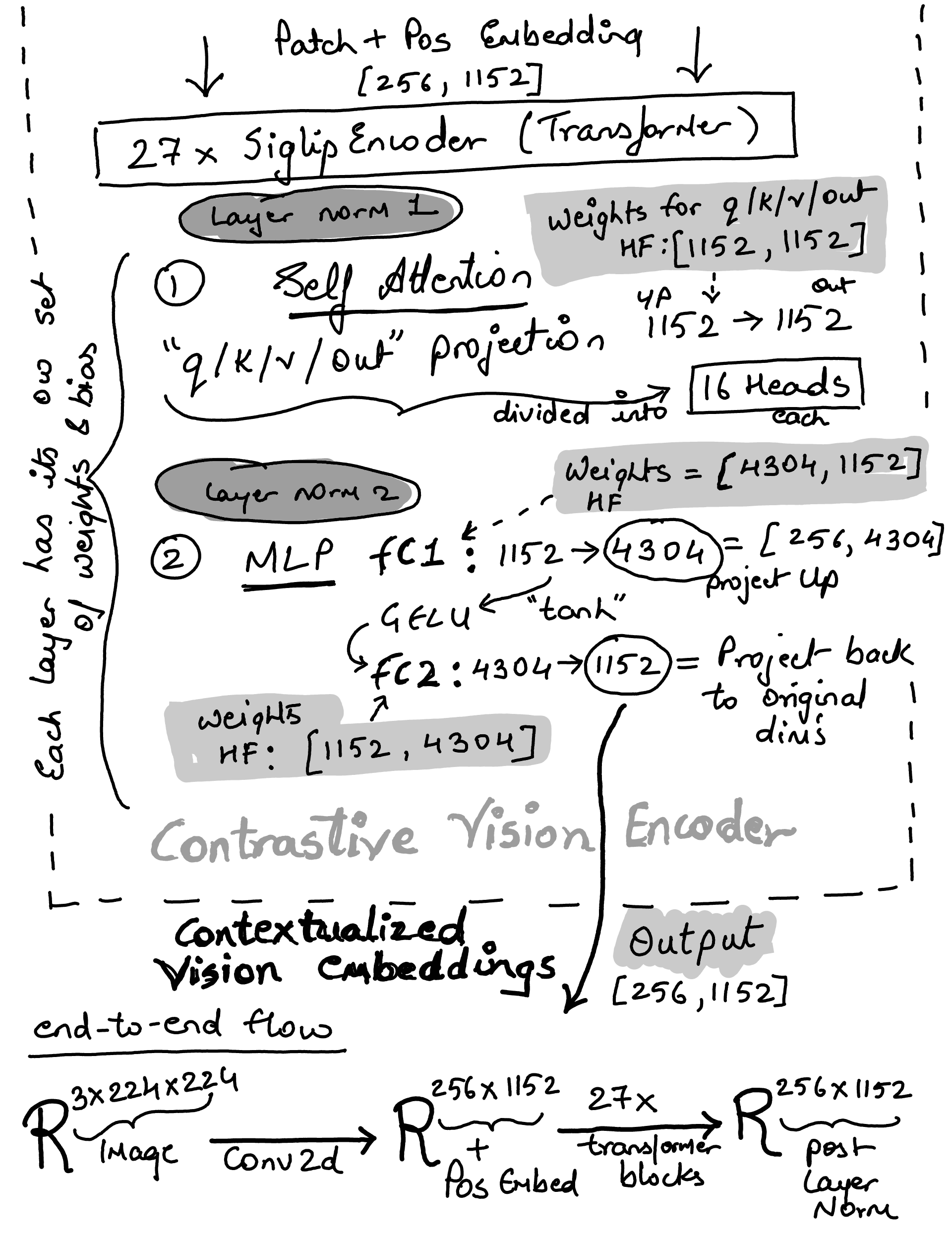
# Transformer block
class SiglipEncoderLayer(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.embed_dim = config.hidden_size
self.self_attn = SiglipAttention(config)
self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
self.mlp = SiglipMLP(config)
self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
) -> torch.Tensor:
# [Batch_size, Num_Patches, Embed_Dim]
residual = hidden_states
hidden_states = self.layer_norm1(hidden_states)
hidden_states, _ = self.self_attn(hidden_states)
hidden_states = residual + hidden_states
residual = hidden_states
hidden_states = self.layer_norm2(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
# [Batch_size, Num_Patches, Embed_Dim]
return hidden_states
class SiglipEncoder(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
self.layers = nn.ModuleList(
[SiglipEncoderLayer(config) for _ in range(config.num_hidden_layers)]
)
def forward(self, input_embeds: torch.Tensor) -> torch.Tensor:
hidden_states = input_embeds
for encoder_layer in self.layers:
# [Batch_Size, Num_Patches, Embed_Dim] -> [Batch_Size, Num_Patches, Embed_Dim]
hidden_states = encoder_layer(hidden_states)
return hidden_states
Siglip ViT Model#
The residual connection (residual + hidden_states) ensure
Training (Gradient Flow): they create a “highway” for gradients to travel back to earlier layers during training. Without this, the gradients would “vanish” (become zero) before reaching the first layers, making it impossible for deep models to learn.
Inference (Feature Preservation): During inference, they act as a “memory” or “safe path”. Instead of a layer having to “re-learn” everything from scratch, it only needs to learn the difference (the “residual”) or small updates to the existing information. This allows the model to preserve the original meaning of tokens as they pass through 27 layers of transformations…
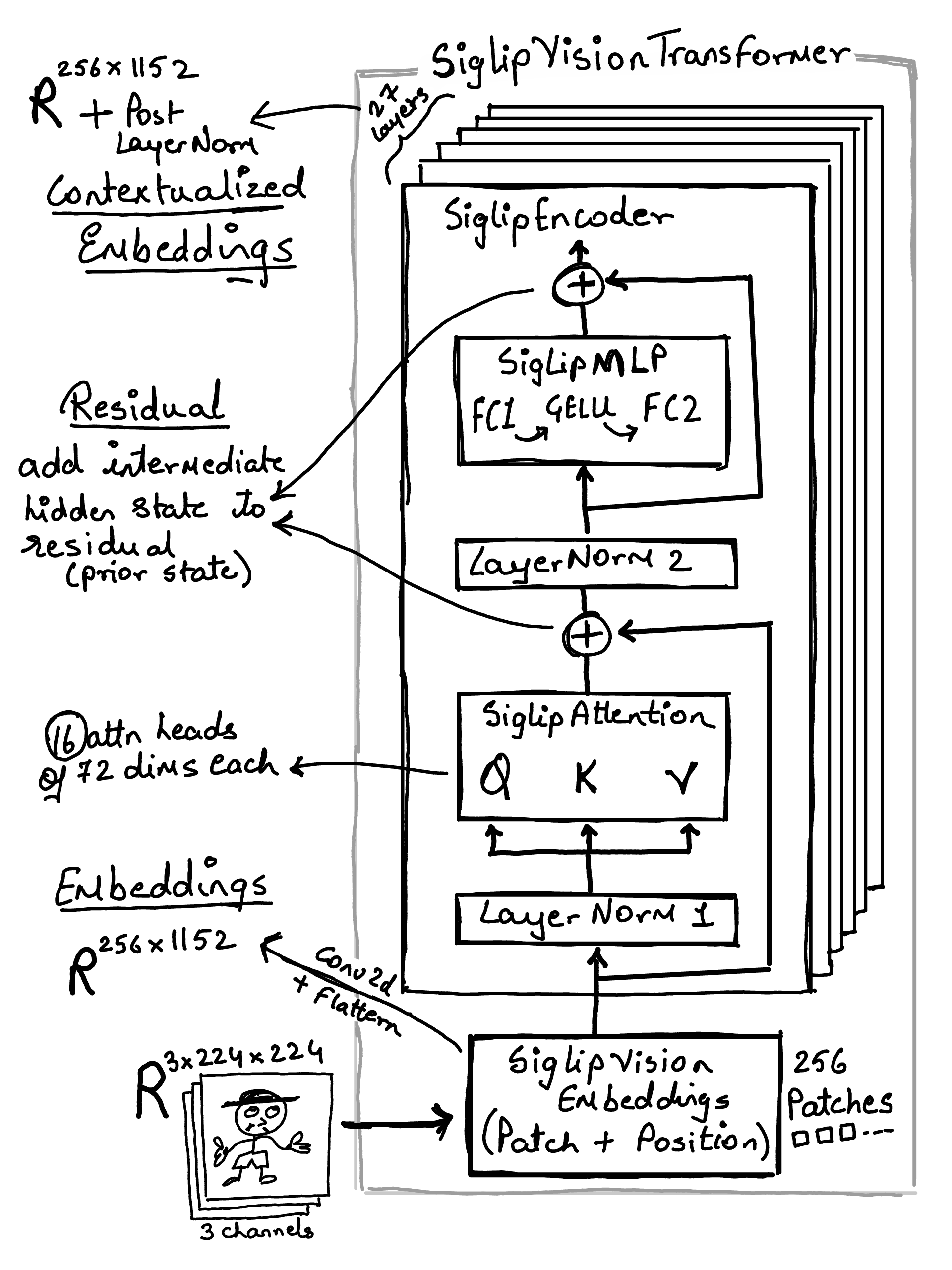
class SiglipVisionTransformer(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
embed_dim = config.hidden_size
self.embeddings = SiglipVisionEmbeddings(config)
self.encoder = SiglipEncoder(config)
self.post_layernorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
def forward(self, pixel_values: torch.Tensor) -> torch.Tensor:
# pixel_values: [Batch_Size, Channels, Height, Width] -> [Batch_Size, Num_Patches, Embed_Dim]
hidden_states = self.embeddings(pixel_values)
last_hidden_state = self.encoder(inputs_embeds=hidden_states)
last_hidden_state = self.post_layernorm(last_hidden_state)
return last_hidden_state
class SiglipVisionModel(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
self.vision_model = SiglipVisionTransformer(config)
def forward(self, pixel_values) -> Tuple:
# [Batch_Size, Channels, Height, Width] -> [Batch_Size, Num_Patches, Embed_Dim]
return self.vision_model(pixel_values=pixel_values)
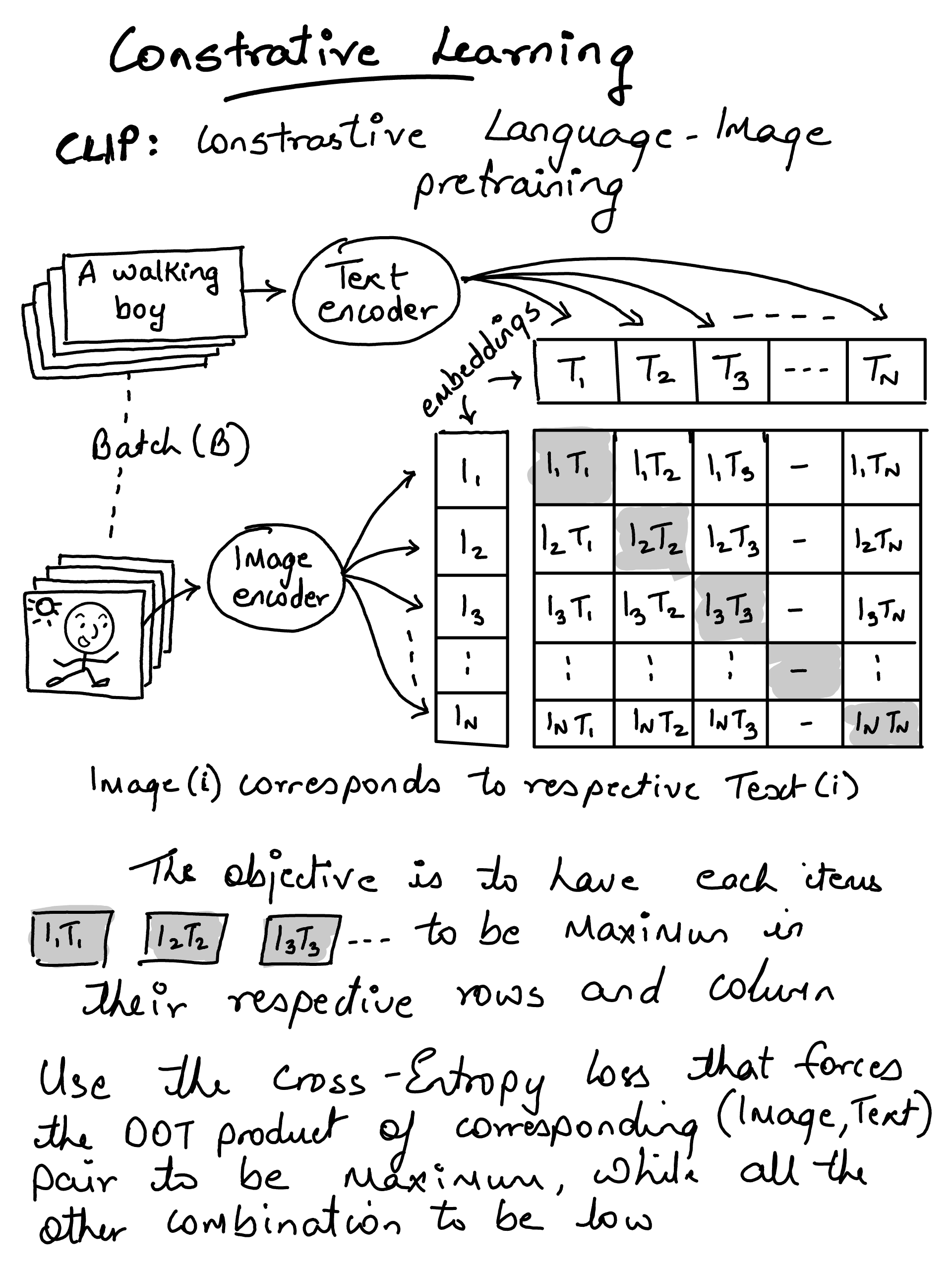
Contrastive Language-Image Pretraining#