◉ Perception Encoder#
Exploring PE and PLM: on 5090
PLM#
Perception Language Model (PLM) is a state-of-the-art, fully open and reproducible MLLM for transparent research in image and video understanding.
![]()
![]()
Login in HF hub#
from huggingface_hub.hf_api import HfFolder
HfFolder.save_token('ZZZZ')
Use nightly built of torch for 5090 in response to below warning:
⚠️⚠️ WARNING ⚠️⚠️ NVIDIA GeForce RTX 5090 with CUDA capability sm_120 is not compatible with the current PyTorch installation. Supported sm_50 sm_60 sm_70 sm_75 sm_80 sm_86 sm_90.
pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 xformers --index-url https://download.pytorch.org/whl/cu128
conda install ffmpeg -c conda-forge
pip install torchcodec==0.4.0
pip install -e .
import torch
print(torch.__version__)
print(torch.cuda.get_arch_list())
print(torch.randn(1).cuda()) # Should match 12.1+
2.7.1+cu128
['sm_75', 'sm_80', 'sm_86', 'sm_90', 'sm_100', 'sm_120', 'compute_120']
tensor([1.1256], device='cuda:0')
import os
import sys
import re
# Add the project root to Python path
sys.path.append('/home/n03an/code/references/perception_models')
import torch
from PIL import Image, ImageDraw
import time
from IPython.display import HTML
from base64 import b64encode
import textwrap
import requests
import urllib.request
from core.args import dataclass_from_dict
from core.transforms.image_transform import get_image_transform
from core.transforms.video_transform import get_video_transform
from apps.plm.generate import PackedCausalTransformerGeneratorArgs, PackedCausalTransformerGenerator, load_consolidated_model_and_tokenizer
Load PLM#
# ckpt = "facebook/Perception-LM-1B"
ckpt = "facebook/Perception-LM-3B"
# ckpt = "facebook/Perception-LM-8B"
model, tokenizer, config = load_consolidated_model_and_tokenizer(ckpt)
Downloading facebook/Perception-LM-3B from Hugging Face Hub...
Fetching 19 files: 100%|██████████| 19/19 [00:00<00:00, 184471.70it/s]
INFO:apps.plm.tokenizer:Reloaded tiktoken model from /home/n03an/.cache/huggingface/hub/models--facebook--Perception-LM-3B/snapshots/31e3665b544e2dbac215e80200923139fb398975/original/tokenizer.model
INFO:apps.plm.tokenizer:#words: 128256 - BOS ID: 128000 - EOS ID: 128001
Downloaded to: /home/n03an/.cache/huggingface/hub/models--facebook--Perception-LM-3B/snapshots/31e3665b544e2dbac215e80200923139fb398975/original
INFO:apps.plm.transformer:Initializing PE_VisionTransformer with args: {'image_size': 448, 'patch_size': 14, 'width': 1024, 'layers': 23, 'heads': 16, 'use_cls_token': True, 'use_abs_posemb': True, 'mlp_ratio': 4.0, 'ls_init_value': 0.1, 'drop_path': 0.1, 'use_ln_post': False, 'pool_type': 'none'}
def generate(
media_path,
question="Describe the image in details.",
media_type="image",
number_of_frames=4,
number_of_tiles=1,
temperature=0.0,
top_p=None,
top_k=None,
return_text=False,
):
prompts = []
if media_type == "image":
transform = get_image_transform(
vision_input_type=(
"vanilla" if number_of_tiles == 1 else config.data.vision_input_type
),
image_res=model.vision_model.image_size,
max_num_tiles=number_of_tiles,
)
if isinstance(media_path, str):
image = Image.open(media_path).convert("RGB")
else:
image = media_path
image, _ = transform(image)
prompts.append((question, image))
elif media_type == "video":
transform = get_video_transform(
image_res=model.vision_model.image_size,
)
video_info = (media_path, number_of_frames, None, None, None)
frames, _ = transform(video_info)
prompts.append((question, frames))
else:
raise NotImplementedError(
f"The provided generate function only supports image and video."
)
# Create generator
gen_cfg = dataclass_from_dict(
PackedCausalTransformerGeneratorArgs,
{"temperature": temperature, "top_p": top_p, "top_k": top_k},
strict=False,
)
generator = PackedCausalTransformerGenerator(gen_cfg, model, tokenizer)
# Run generation
start_time = time.time()
generation, loglikelihood, greedy = generator.generate(prompts)
end_time = time.time()
if return_text:
print(generation[0])
return generation[0]
for i, gen in enumerate(generation):
# Calculate tokens per second
total_tokens = sum(
len(tokenizer.encode(gen, False, False)) for gen in generation
)
tokens_per_second = total_tokens / (end_time - start_time)
print("=================================================")
print(textwrap.fill(gen, width=75))
print(f"Tokens per second: {tokens_per_second:.2f}")
print("=================================================")
def extract_all_bounding_boxes(text: str) -> list[list[str]]:
"""Extracts any list of arbitrary length from a string."""
pattern = r"\[\s*([^\[\]]*?)\s*\]"
extracted_lists = [
[num.strip() for num in match.split(",")] for match in re.findall(pattern, text)
]
return extracted_lists
def rescale_2d_bboxes(bboxes, img_w, img_h, box_format="000", verbose=True):
w, h = img_w, img_h
rescaled_bboxes = []
for bbox in bboxes:
try:
if box_format == "000":
bbox = [float("0." + b.strip()) for b in bbox]
elif box_format == "standard":
bbox = [float(b.strip()) for b in bbox]
else:
# we don't know the format. try both
try:
bbox = [float("0." + b.strip()) for b in bbox]
except:
bbox = [float(b.strip()) for b in bbox]
x1, y1, x2, y2 = bbox
bbox = [x1 * w, y1 * h, x2 * w, y2 * h]
rescaled_bboxes.append(bbox)
except Exception as e:
if verbose:
print("[rescale_2d_bboxes]:", e, bbox, flush=True)
pass
return rescaled_bboxes
def postprocess_grounding(x: str, img_w: int, img_h: int) -> list[float]:
bboxes = extract_all_bounding_boxes(x)
bboxes = rescale_2d_bboxes(bboxes, img_w, img_h)
if len(bboxes) > 0:
box = bboxes[0]
else:
# no box found.
box = [0, 0, img_w, img_h]
return box
def generate_grounding(media_path: str, question: str, number_of_tiles: int):
image = Image.open(media_path)
w, h = image.size
print("Generating...")
output = generate(media_path=media_path, question=question, number_of_tiles=number_of_tiles, media_type="image", return_text=True)
box = postprocess_grounding(output, w, h)
draw = ImageDraw.Draw(image)
try:
x_min, y_min, x_max, y_max = box
if x_min < x_max and y_min < y_max:
# Draw the bounding box
draw.rectangle([x_min, y_min, x_max, y_max], outline="red", width=2)
except Exception as e:
print(f"Error drawing bounding box: {e}")
return image
Run inference for image grounding task#
question_template = "Provide a bounding box of the region this sentence describes: '{caption}'.\nUse the format [x1, y1, x2, y2]."
image_url = "http://farm3.staticflickr.com/2453/3867429392_ed6f3d337a_z.jpg"
image_path = "3867429392_ed6f3d337a_z.jpg"
urllib.request.urlretrieve(image_url, image_path)
description = "white fire hydrant in the back"
question = question_template.format(caption=description)
img = Image.open(image_path)
display(img)
img_drawn = generate_grounding(media_path=image_path, question=question, number_of_tiles=36)
display(img_drawn)

INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
Generating...
[040,490,109,570]

Region captioning (bounding box as text)#
question = "Please describe the region ({bbox}) in details.\nThe region is in the format of [x1, y1, x2, y2]."
question = question.format(bbox="[040,482,112,576]")
generate(media_path=img_drawn, question=question, number_of_tiles=36, media_type="image")
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
=================================================
fire hydrant in the background
Tokens per second: 1.29
=================================================
Region captioning (bounding box as drawing)#
question = "Please describe the region inside the rec rectangle."
generate(media_path=img_drawn, question=question, number_of_tiles=36, media_type="image")
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
=================================================
[040,482,109,572]
Tokens per second: 7.43
=================================================
Testing on samples from VIRAT Dataset#
question_template = "Provide a bounding box of the region this sentence describes: '{caption}'.\nUse the format [x1, y1, x2, y2]."
image_path = "condo_parking.png"
description = "person walking with umbrella"
question = question_template.format(caption=description)
img = Image.open(image_path)
display(img)
img_drawn = generate_grounding(media_path=image_path, question=question, number_of_tiles=36)
display(img_drawn)

INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
Generating...
[231,720,255,833]

Injecting bounding boxes from YOLOE#
from ultralytics import YOLOE
yoloe_model = YOLOE("yoloe-11l-seg-pf.pt")
import matplotlib.pyplot as plt
from IPython.display import display, Image
def detect_objects(image_path, model=yoloe_model):
results = model(image_path)
plt.figure(figsize=(12, 8))
plt.imshow(results[0].plot()[:, :, ::-1])
plt.axis("off")
plt.show()
return results
results = detect_objects("condo_parking.png")
# print(results)
image 1/1 /home/n03an/code/references/perception_models/apps/plm/notebook_demos/condo_parking.png: 384x640 2 barrels, 20 cars, 1 emergency vehicle, 1 information desk, 1 recycling bin, 1 shipping container, 6 suvs, 1 tow truck, 2 trailer trucks, 4 vans, 1 waste container, 39.9ms
Speed: 1.9ms preprocess, 39.9ms inference, 9.8ms postprocess per image at shape (1, 3, 384, 640)
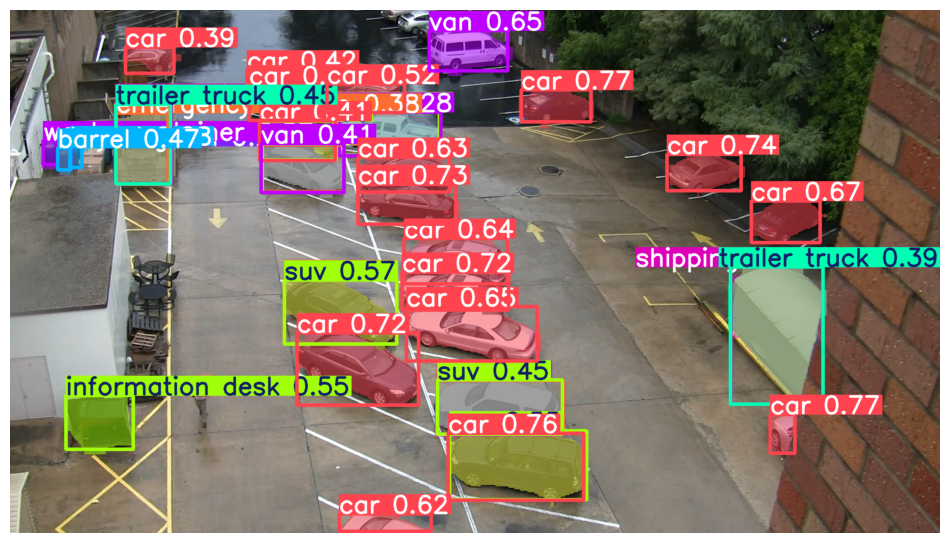
Cleanup image to keep only the bounding boxes
from PIL import Image, ImageDraw
img_drawn = Image.open("condo_parking.png")
draw = ImageDraw.Draw(img_drawn)
for box in results[0].boxes:
x1, y1, x2, y2 = box.xyxy[0].tolist()
cls = int(box.cls[0])
draw.rectangle([x1, y1, x2, y2], outline="red", width=2)
draw.text((x1, y1), str(cls), fill="red")
img_drawn.show()

Inference using the bbbox from YOLOE
question = "Given a list of regions ({bbox}), describe each region in detail.\nThe region is in the format of [x1, y1, x2, y2]."
question = question.format(bbox=str(results[0].boxes.xyxy.tolist()))
print(question)
generate(media_path=img_drawn, question=question, number_of_tiles=36, media_type="image")
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
Given a list of regions ([[1055.907958984375, 166.67059326171875, 1199.28271484375, 232.6873779296875], [1569.0347900390625, 835.081787109375, 1620.7767333984375, 915.9642333984375], [904.4067993164062, 874.775390625, 1184.998291015625, 1012.383544921875], [1356.87841796875, 299.5640869140625, 1509.678466796875, 374.88604736328125], [718.4602661132812, 361.9792785644531, 920.3095092773438, 443.2321472167969], [809.491943359375, 542.8463745117188, 1029.044189453125, 620.627685546875], [592.3390502929688, 667.2838745117188, 843.1241455078125, 816.3665771484375], [1530.1661376953125, 395.6509094238281, 1672.77099609375, 481.7243957519531], [865.474365234375, 44.66704559326172, 1027.41259765625, 127.0682373046875], [818.4708251953125, 613.285400390625, 1088.744384765625, 725.915283203125], [813.5240478515625, 472.24884033203125, 1026.7803955078125, 566.2918090820312], [718.8458251953125, 305.9491882324219, 907.4540405273438, 377.5452575683594], [679.593994140625, 1040.403076171875, 869.1578369140625, 1076.3095703125], [566.4322509765625, 558.3406982421875, 798.9175415039062, 690.7618408203125], [566.3768920898438, 557.79541015625, 798.870849609375, 690.9448852539062], [115.34028625488281, 796.808349609375, 254.01187133789062, 907.4794921875], [907.5245361328125, 869.864501953125, 1190.736328125, 1011.8411865234375], [654.5325927734375, 154.59243774414062, 814.1592407226562, 213.017333984375], [98.18843078613281, 286.7320861816406, 125.93412780761719, 331.06549072265625], [218.403076171875, 196.6102752685547, 331.19952392578125, 360.74072265625], [882.6234741210938, 764.5292358398438, 1140.887939453125, 876.4059448242188], [881.64990234375, 765.260009765625, 1142.0595703125, 876.714111328125], [881.8800659179688, 764.2064208984375, 1140.34765625, 877.5531005859375], [493.6552734375, 156.16937255859375, 649.2734375, 229.53030395507812], [489.9690856933594, 125.33489227294922, 609.1558837890625, 165.96951293945312], [518.6258544921875, 277.63067626953125, 689.021240234375, 378.22918701171875], [515.8487548828125, 230.30799865722656, 671.5083618164062, 312.4571533203125], [217.7808837890625, 194.8688507080078, 333.8619689941406, 360.88525390625], [520.1320190429688, 278.1162109375, 689.9099731445312, 378.905029296875], [238.57997131347656, 78.4800796508789, 338.61602783203125, 132.6048583984375], [1487.9527587890625, 531.4498901367188, 1678.8438720703125, 814.0872802734375], [219.56698608398438, 214.45811462402344, 326.6293029785156, 361.3482666015625], [1488.176025390625, 531.3645629882812, 1678.5810546875, 814.4005126953125], [515.9783935546875, 231.59841918945312, 673.5609130859375, 311.1498107910156], [519.9911499023438, 280.01165771484375, 689.618896484375, 376.92181396484375], [123.79180908203125, 281.9728088378906, 148.2416534423828, 326.42376708984375], [679.5899658203125, 212.58888244628906, 889.1549072265625, 302.16455078125], [68.47206115722656, 271.57977294921875, 98.42008209228516, 320.25762939453125], [680.17138671875, 211.77749633789062, 886.9091796875, 301.7431640625], [98.52893829345703, 282.4366455078125, 126.19361114501953, 331.3118896484375]]), describe each region in detail.
The region is in the format of [x1, y1, x2, y2].
=================================================
a car parked in a parking lot.
Tokens per second: 1.18
=================================================
question = "Please describe region inside each rectangles in details."
generate(media_path=img_drawn, question=question, number_of_tiles=36, media_type="image")
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
=================================================
the video shows a parking lot with many cars parked in it. the cars are
parked in a straight line and are of different colors and models. there are
also some other objects in the parking lot such as a truck, a van, and some
barrels. the parking lot is wet, indicating that it has been raining
recently."
Tokens per second: 3.91
=================================================
question = "Count total vehicles by type identified by each red bounding box"
generate(media_path=img_drawn, question=question, number_of_tiles=36, media_type="image")
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
=================================================
the total number of cars is 24, the total number of trucks is 2, the total
number of vans is 1, and the total number of SUVs is 2
Tokens per second: 3.38
=================================================
question = "describe the man in detail"
generate(media_path=img_drawn, question=question, number_of_tiles=36, media_type="image")
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
=================================================
the man is wearing a white shirt and black pants. he is holding an orange
umbrella in his right hand. he is walking towards the left side of the
frame. he is also wearing a black cap
Tokens per second: 3.39
=================================================
question = "describe all people visible in the image"
generate(media_path=img_drawn, question=question, number_of_tiles=36, media_type="image")
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
=================================================
There is one person visible in the image. The person is walking in the
parking lot with an umbrella.
Tokens per second: 2.65
=================================================
!nvidia-smi
Sat Nov 29 18:26:17 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.82.02 Driver Version: 581.15 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 5090 On | 00000000:02:00.0 On | N/A |
| 0% 45C P8 33W / 575W | 31980MiB / 32607MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 33 G /Xwayland N/A |
+-----------------------------------------------------------------------------------------+
!free -h
total used free shared buff/cache available
Mem: 54Gi 12Gi 39Gi 89Mi 3.8Gi 42Gi
Swap: 14Gi 0B 14Gi
orig_img = Image.open("crowd.jpg")
orig_img

question = "describe all people visible in the image?"
generate(media_path=orig_img, question=question, number_of_tiles=36, media_type="image")
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
=================================================
The image shows a large group of people walking on a crosswalk. The people
are of various ages and ethnicities. Some are carrying bags, purses, or
other items. Some are wearing casual clothing, while others are dressed
more formally.
Tokens per second: 3.51
=================================================
question = "Identify person wearing pink top and red pants carrying a pink bag. Describe the person in details such as gender, age, ethinicity, top color, bottom color, head gear, and their behavior"
generate(media_path=orig_img, question=question, number_of_tiles=36, media_type="image")
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
=================================================
The person in question is a woman, who appears to be of Asian descent. She
is wearing a pink top and red pants, and is carrying a pink bag. She is
walking and seems to be in a hurry.
Tokens per second: 3.37
=================================================
Grounding Test#
question_template = "Provide a bounding box of the region this sentence describes: '{caption}'.\nUse the format [x1, y1, x2, y2]."
description = "pink bag"
question = question_template.format(caption=description)
img_drawn = generate_grounding(media_path="crowd.jpg", question=question, number_of_tiles=36)
display(img_drawn)
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
Generating...
[503,637,581,898]

question_template = "Provide a bounding box of the region this sentence describes: '{caption}'.\nUse the format [x1, y1, x2, y2]."
description = "young girl in blue top"
question = question_template.format(caption=description)
img_drawn = generate_grounding(media_path="crowd.jpg", question=question, number_of_tiles=36)
display(img_drawn)
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
Generating...
[000,243,999,999]

question_template = "Provide a bounding box of the region this sentence describes: '{caption}'.\nUse the format [x1, y1, x2, y2]."
description = "women in blue scarf"
question = question_template.format(caption=description)
img_drawn = generate_grounding(media_path="crowd.jpg", question=question, number_of_tiles=36)
display(img_drawn)
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
Generating...
[581,453,647,728]

Alternate Crowd Image#
question_template = "Provide a bounding box of the region this sentence describes: '{caption}'.\nUse the format [x1, y1, x2, y2]."
description = "person in blue tshirt carrying bag"
question = question_template.format(caption=description)
img_drawn = generate_grounding(media_path="crowd_2.webp", question=question, number_of_tiles=36)
display(img_drawn)
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
Generating...
[543,476,616,647]

orig_img = Image.open("crowd_2.webp")
question = "describe the person in detail carrying yellow backpack"
generate(media_path=orig_img, question=question, number_of_tiles=36, media_type="image")
INFO:root:VariableSizeImageTransform size: 448
INFO:root:ImageTransform size: 448
INFO:root:Initialized transforms with: vision_input_type: 'thumb+tile' and max_num_tiles: 36.
=================================================
The person in the image is a woman with long dark hair. She is wearing a
white shirt, black pants, and a yellow backpack. She is also carrying a
pink bag in her left hand.
Tokens per second: 16.89
=================================================
Testing Perception Encoder Core - PE-Core-L14-336#
import torch
from PIL import Image
import core.vision_encoder.pe as pe
import core.vision_encoder.transforms as transforms
# print("CLIP configs:", pe.CLIP.available_configs())
# CLIP configs: ['PE-Core-G14-448', 'PE-Core-L14-336', 'PE-Core-B16-224', 'PE-Core-S16-384', 'PE-Core-T16-384']
model = pe.CLIP.from_config("PE-Core-L14-336", pretrained=True) # Downloads from HF
model = model.cuda()
preprocess = transforms.get_image_transform(model.image_size)
tokenizer = transforms.get_text_tokenizer(model.context_length)
orig_img = Image.open("condo_parking.png")
orig_img.show()
image = preprocess(orig_img).unsqueeze(0).cuda()
def test(labels):
text = tokenizer(labels).cuda()
with torch.no_grad(), torch.autocast("cuda"):
image_features, text_features, logit_scale = model(image, text)
text_probs = (logit_scale * image_features @ text_features.T).softmax(dim=-1)
print("=============> ⭕ Results for labels:", labels)
for label, prob in zip(labels, text_probs[0]):
print(f"{label}: {prob*100}")
test(["black sedan", "blue umbrella"])
test(["man with blue umbrella", "women with orange umbrella"])
test(["black sedan", "white truck"])
test(["chairs and tables", "white barrels", "blue barrels"])
INFO:root:Missing keys for loading model: []
INFO:root:Unexpected keys for loading model: []
Missing keys for loading model: []
Unexpected keys for loading model: []
=============> ⭕ Results for labels: ['black sedan', 'blue umbrella']
black sedan: 0.0009818327380344272
blue umbrella: 99.9990234375
=============> ⭕ Results for labels: ['man with blue umbrella', 'women with orange umbrella']
man with blue umbrella: 58.888912200927734
women with orange umbrella: 41.111083984375
=============> ⭕ Results for labels: ['black sedan', 'white truck']
black sedan: 87.83142852783203
white truck: 12.168575286865234
=============> ⭕ Results for labels: ['chairs and tables', 'white barrels', 'blue barrels']
chairs and tables: 26.0778751373291
white barrels: 65.04957580566406
blue barrels: 8.872550010681152
Testing Siglip 2#
from transformers import AutoProcessor, SiglipModel
import torch
model_id = "google/siglip-so400m-patch14-384"
device = ("cuda" if torch.cuda.is_available() else "cpu")
processor = AutoProcessor.from_pretrained(model_id)
model = SiglipModel.from_pretrained(model_id).to(device).eval()
/home/n03an/miniconda3/envs/perception_models/lib/python3.12/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
model
SiglipModel(
(text_model): SiglipTextTransformer(
(embeddings): SiglipTextEmbeddings(
(token_embedding): Embedding(32000, 1152)
(position_embedding): Embedding(64, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(self_attn): SiglipAttention(
(k_proj): Linear(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear(in_features=1152, out_features=1152, bias=True)
(q_proj): Linear(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear(in_features=1152, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): PytorchGELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
)
)
)
(final_layer_norm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(head): Linear(in_features=1152, out_features=1152, bias=True)
)
(vision_model): SiglipVisionTransformer(
(embeddings): SiglipVisionEmbeddings(
(patch_embedding): Conv2d(3, 1152, kernel_size=(14, 14), stride=(14, 14), padding=valid)
(position_embedding): Embedding(729, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(self_attn): SiglipAttention(
(k_proj): Linear(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear(in_features=1152, out_features=1152, bias=True)
(q_proj): Linear(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear(in_features=1152, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): PytorchGELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
)
)
)
(post_layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(head): SiglipMultiheadAttentionPoolingHead(
(attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=1152, out_features=1152, bias=True)
)
(layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): PytorchGELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
)
)
)
SigLIP 2 Retrieval Pipelien (image emb, text emb, search)#
Simple Siglip2 reterivel pipeline for
generating embeddings (image and text)
Given user query, perform similarity search on image embeddings and show probabilities (sigmoid) accross images…
from typing import List, Dict
import torch
from PIL import Image
import torch.nn.functional as F
class SiglipRetriever:
def __init__(self, model, processor, device):
self.device = device
self.processor = processor
self.model = model
@torch.inference_mode()
def image_emb(self, image: Image.Image):
inputs = self.processor(images=image, text=[""], return_tensors="pt", padding="max_length").to(self.device)
out = self.model(**inputs)
return out.image_embeds[0] # normalized
@torch.inference_mode()
def text_emb(self, texts: List[str]):
dummy = Image.new("RGB", (224, 224), color=(0, 0, 0))
inputs = self.processor(images=dummy, text=texts, return_tensors="pt", padding="max_length").to(self.device)
out = self.model(**inputs)
return out.text_embeds # (B, D) normalized
@torch.inference_mode()
def search(self, query: str, image_matrix: torch.Tensor, meta: List[Dict], k=5):
q = self.text_emb([query])[0] # (D,)
cos = (image_matrix @ q) # cosine similarities (N,)
logit_scale = self.model.logit_scale.exp()
logit_bias = self.model.logit_bias # scalar parameter
logits_no_bias = logit_scale * cos
logits = logits_no_bias + logit_bias # match forward()
vals, idxs = torch.topk(logits, k=min(k, logits.shape[0]))
probs = torch.sigmoid(vals)
return [
{
"logit": float(v), # scaled + bias (official)
"logit_no_bias": float(logits_no_bias[i]),
"cosine": float(cos[i]),
"prob_percent": float(p * 100),
**meta[i],
}
for v, p, i in zip(vals.tolist(), probs.tolist(), idxs.tolist())
]
import base64
import io
def to_b64(img: Image.Image, max_size=(140,140)):
img = img.copy()
img.thumbnail(max_size)
buf = io.BytesIO()
img.save(buf, format='JPEG')
img_b64 = base64.b64encode(buf.getvalue()).decode('utf-8')
return f"<img src='data:image/jpeg;base64,{img_b64}' style='width:{max_size[0]}px;height:auto;border-radius:4px;'/>"
def display_search_results(results, query):
print(f"=== Search Results for query: '{query}' ===>")
for r in results:
display(HTML(to_b64(r['image'])))
print(f"Path: {r['path']}")
print(f" Logit: {r['logit']:.4f} (no bias: {r['logit_no_bias']:.4f})")
print(f" Cosine similarity: {r['cosine']:.4f}")
print(f" Probability: {r['prob_percent']:.2f}%")
print()
Using SAHI to maintain AR and perform sliced inference for enhance object detection#
from IPython.display import Image
# Correct local sahi imports (after ensuring repo root is on sys.path in previous cell)
from sahi import AutoDetectionModel
from sahi.predict import get_prediction, get_sliced_prediction, predict
# YOLOE with sahi havent been released yet, so we use RT-DETR
detection_model = AutoDetectionModel.from_pretrained(
model_type="rtdetr",
model_path="rtdetr-l.pt", # any yoloe-11s-seg.pt, yoloe-11m-seg.pt, yoloe-11l-seg.pt,yoloe-v8s-seg.pt, yoloe-v8m-seg.pt, yoloe-v8l-seg.pt model is supported # noqa: E501
confidence_threshold=0.35
)
result = get_sliced_prediction(
"crowd_2.webp",
detection_model,
slice_height=480,
slice_width=480,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2,
)
result.export_visuals(export_dir="output/", hide_conf=True, rect_th=1)
Image("output/prediction_visual.png")
Performing prediction on 12 slices.

Create embedings for all images#
from PIL import Image
import torch
from IPython.display import display, HTML
retriever = SiglipRetriever(model, processor, device)
image_sources = {
"crowd_2": "crowd_2.webp",
"blue": "blue.jpg",
"crowd_1": "crowd.jpg",
"parking": "condo_parking.png",
"school": "students.png",
}
emb_list = []
vector_db = []
for p in image_sources.values():
image = Image.open(p).convert("RGB")
print(f"Indexing image from path: {p}")
display(HTML(to_b64(image, max_size=(600,600))))
emb = retriever.image_emb(image)
emb_list.append(emb)
vector_db.append({"path": p, "image": image, "embedding": emb})
images_emb = torch.stack(emb_list) # (N, D)
images_emb.shape
Indexing image from path: crowd_2.webp

Indexing image from path: blue.jpg

Indexing image from path: crowd.jpg

Indexing image from path: condo_parking.png

Indexing image from path: students.png

torch.Size([5, 1152])
User query#
query = "person in blue tshirt carrying bag"
results = retriever.search(query, images_emb, vector_db, k=len(vector_db))
display_search_results(results, query)
=== Search Results for query: 'person in blue tshirt carrying bag' ===>

Path: blue.jpg
Logit: 1.3006 (no bias: 17.8470)
Cosine similarity: 0.1589
Probability: 78.59%

Path: crowd_2.webp
Logit: -4.9634 (no bias: 11.5831)
Cosine similarity: 0.1031
Probability: 0.69%

Path: crowd.jpg
Logit: -6.1819 (no bias: 10.3646)
Cosine similarity: 0.0923
Probability: 0.21%

Path: students.png
Logit: -8.4898 (no bias: 8.0566)
Cosine similarity: 0.0717
Probability: 0.02%

Path: condo_parking.png
Logit: -13.2953 (no bias: 3.2511)
Cosine similarity: 0.0289
Probability: 0.00%