◉ Vision Transformers#
notes to explore ViT, CLIP and SigLIP
ViT#
An Image is Worth 16x16 Words paper
![]()
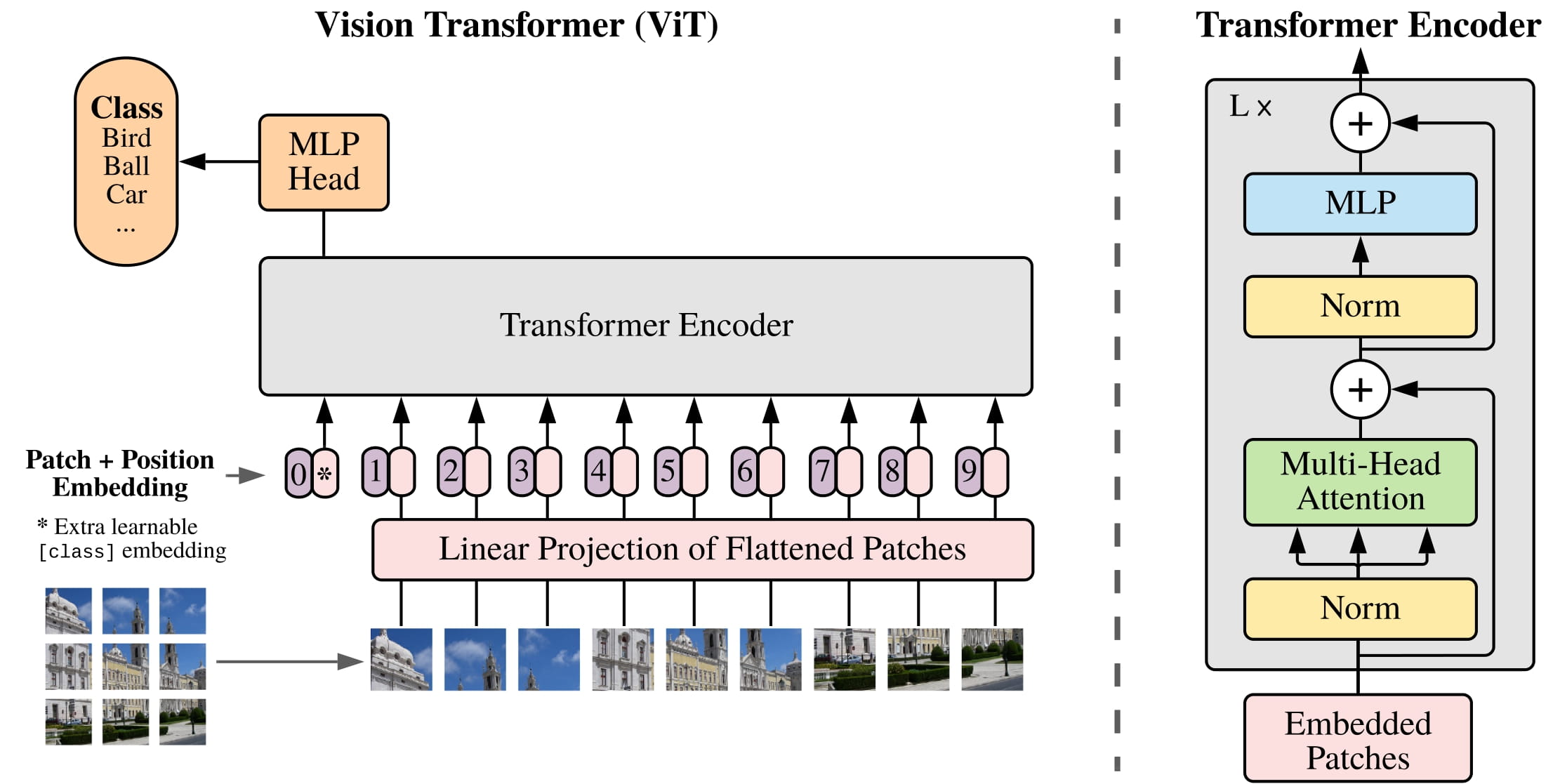
The high level architecture of ViT (Vision Transformer)…
We split an image into fixed-size patches where each patch is flattened and projected into an embedding vector
Because transformers are order-agnostic, we add positional embedding together with the patches embedding
Consider these path+position embedding as tokens that go through Transformer encoder blocks - where each patch attend to every other patch to build short and long spatial relationships
Lastly the tokens go through a non-linear transformation (MLP or feed forward neural net) independently to re-map and enrich its representation / features e.g. for a cat image, if the self attention lets the “cat’s ear” patch interact with the “cat’s face” and “background” patches to builds a spatial understanding of where the cat is. the MLP refines each patch’s internal features / representation i.e. the “cat’s ear” patch might encode “pointed + white fur + edge shape”
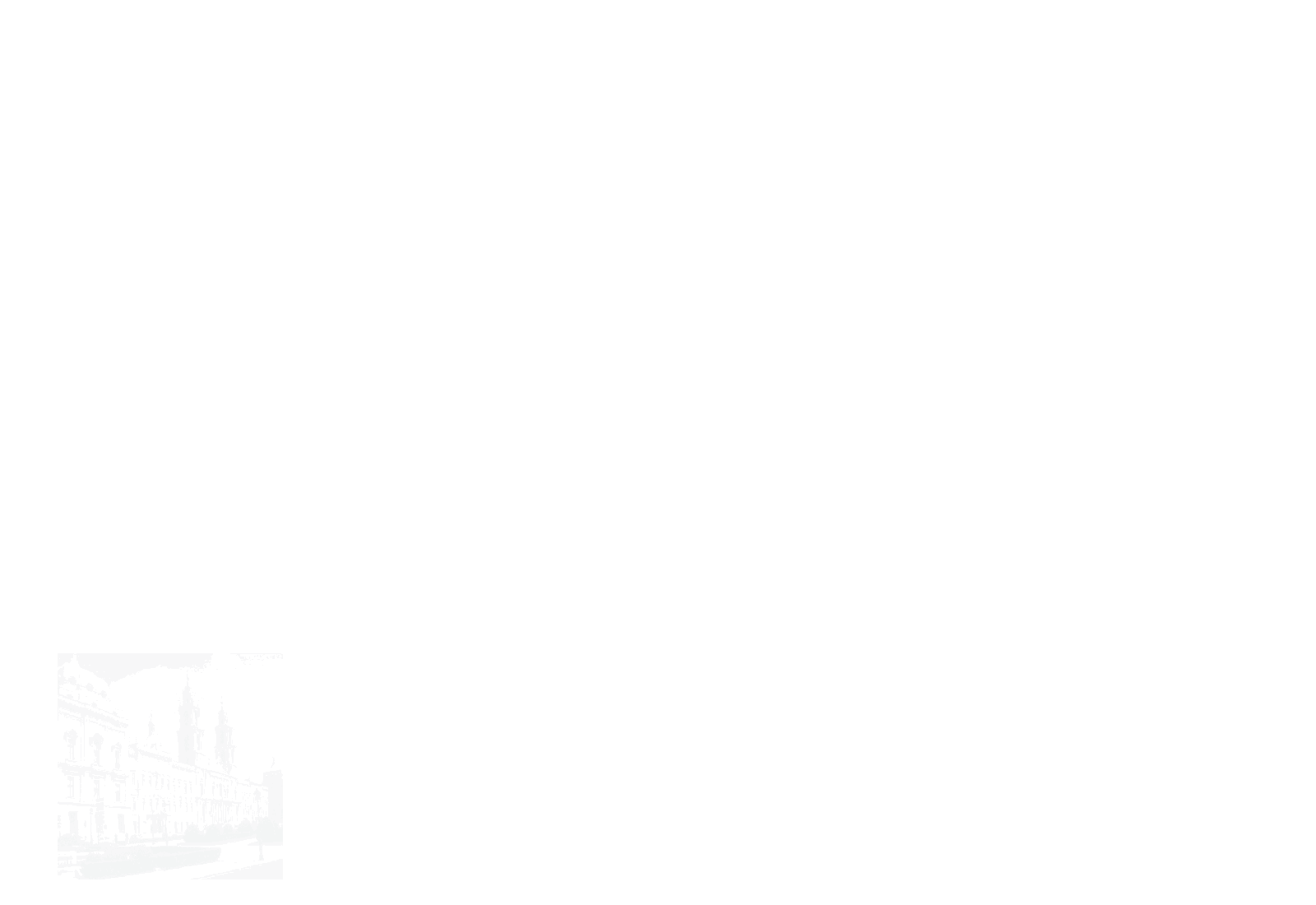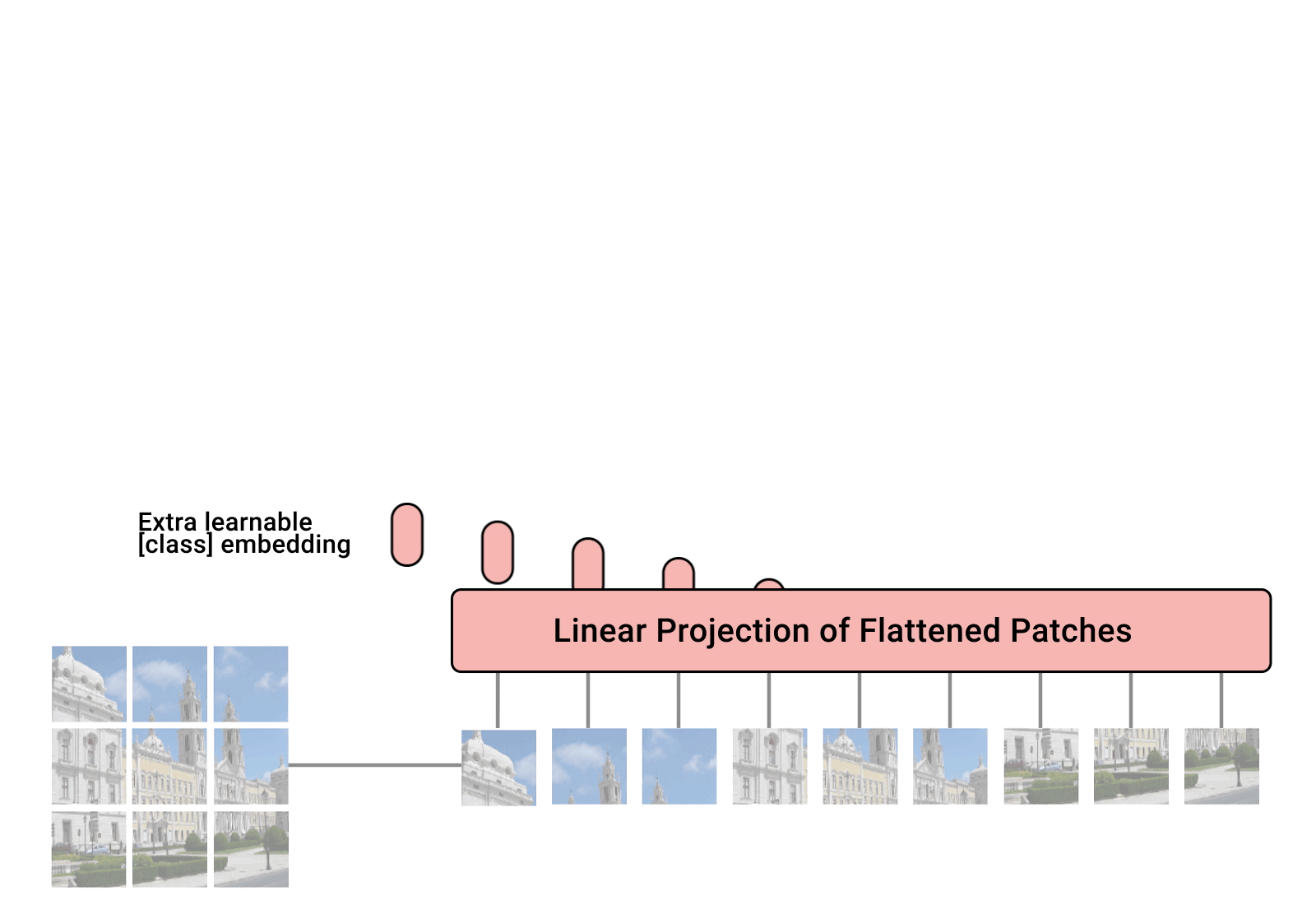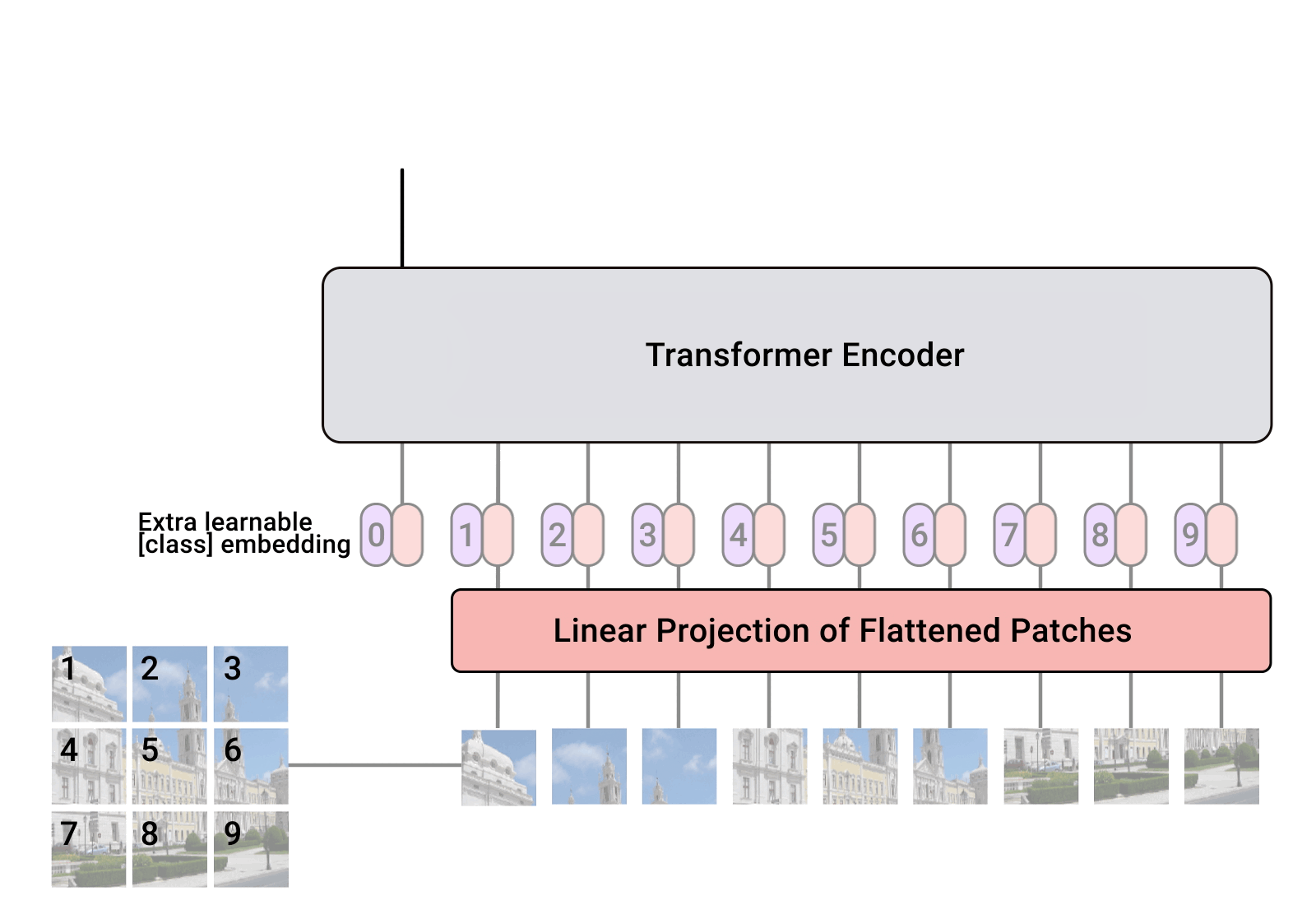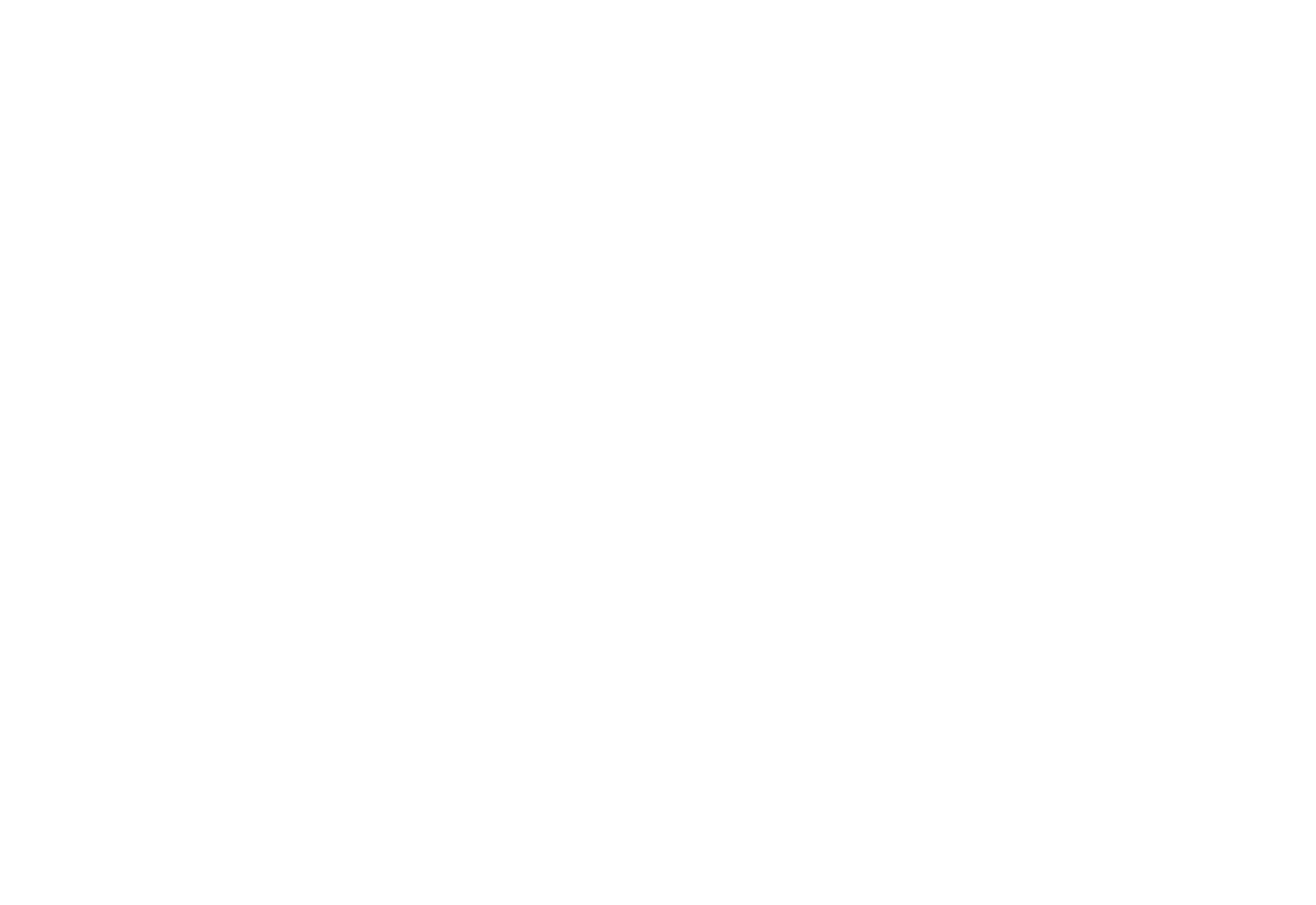
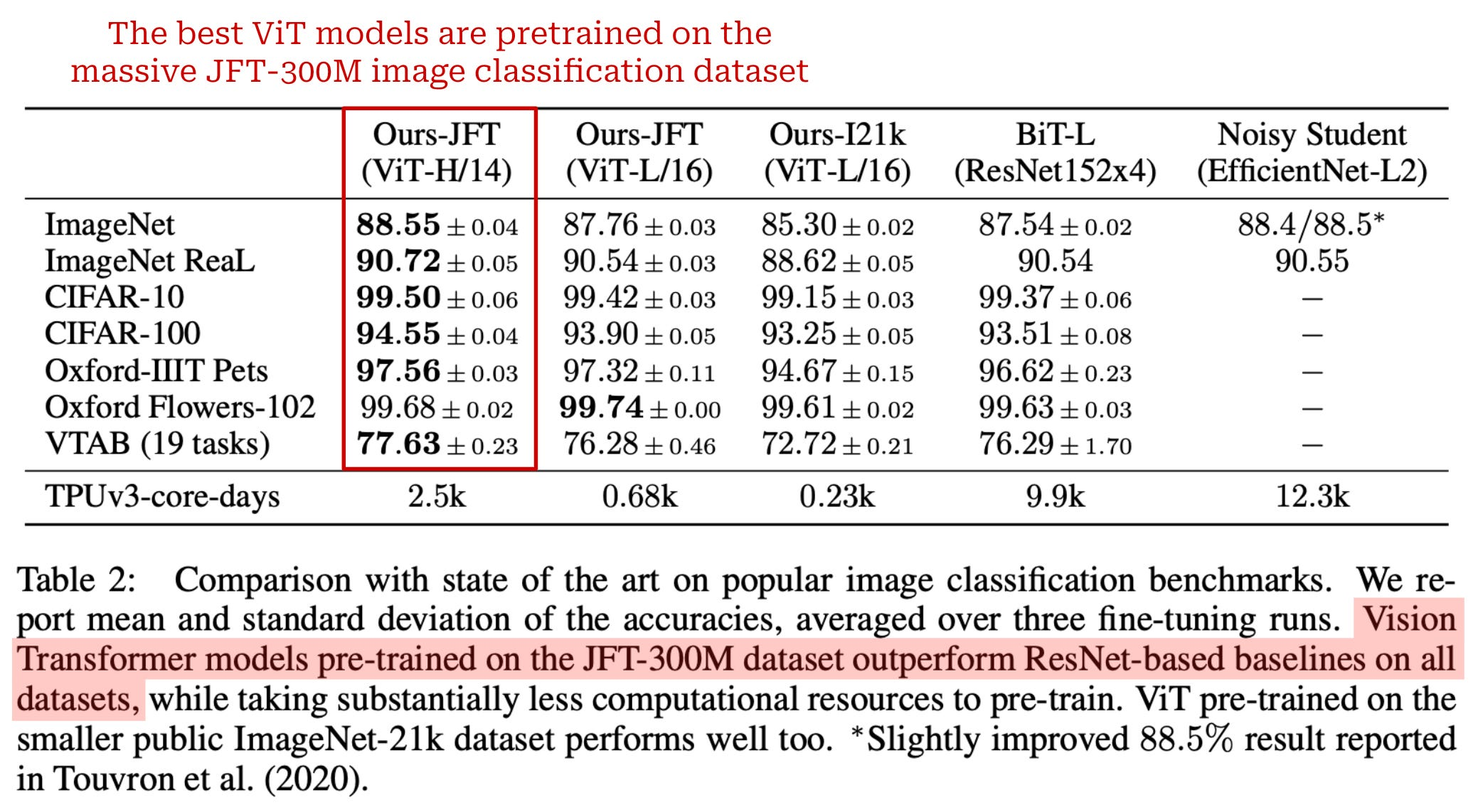
Training ViT. The original ViT model in shares the same architecture as BERT. ViT models are trained using supervised image classification on datasets of varying sizes. When ViTs are trained over small or mid-sized datasets (e.g., ImageNet), they perform comparably to—or slightly worse than ResNets3 of comparable size. However, ViTs begin to shine when pretrained over much larger datasets (e.g., JFT-300M) and finetuned afterwards on downstream tasks
The standard ViT is trained over a large dataset of supervised image classification examples. These models perform best when pretrained over a massive volume of annotated (usually by humans) data, which is difficult and expensive to obtain… an alternative approach was explored that uses image-caption pairs, which are more readily available online, to train a powerful image representation model. This approach is called Contrastive Language-Image Pre-Training (CLIP).
CLIP model#
CLIP
“The simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet.” - OpenAI
CLIP architecture. The CLIP model is made up of two independent components: an image encoder and a text encoder. Given an image-text pair as input, we pass these inputs separately to their corresponding encoder to get an associated vector representation. The image encoder is a standard ViT model, whereas the text encoder is a decoder-only transformer (i.e., a typical GPT-style LLM). CLIP’s text encoder is not used to generate text, but uses a decoder-only architecture to simplify the extension of CLIP to generative applications in the future (such as VLM).
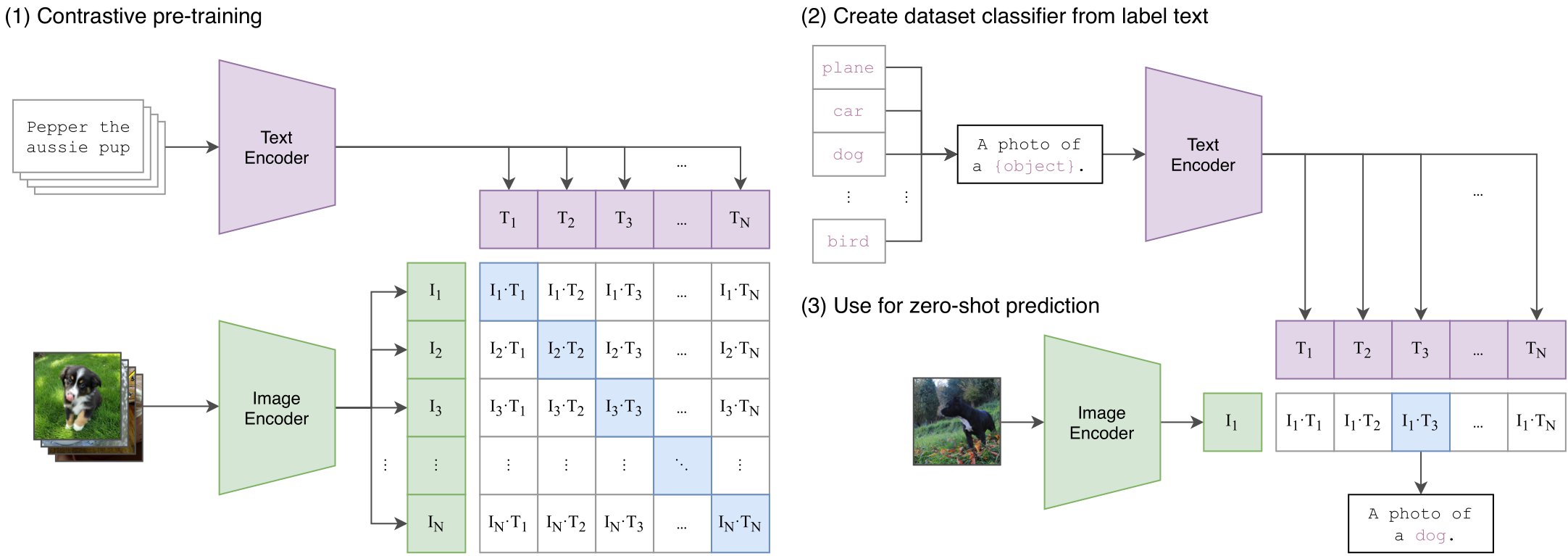
CLIP overview. Taken from the original paper
![]()
Contrastive Learning CLIP is trained using the simple task of classifying the correct caption for an image among a group of candidate captions (i.e., all other captions within a training batch).
Passing a group of images and textual captions through their respective encoders (i.e., the ViT for images and the LLM for text).
Maximizing the cosine similarity between image and text embeddings (obtained from the encoders) of the true image-caption pairs.
Minimizing the cosine similarity between all other image-caption pairs.
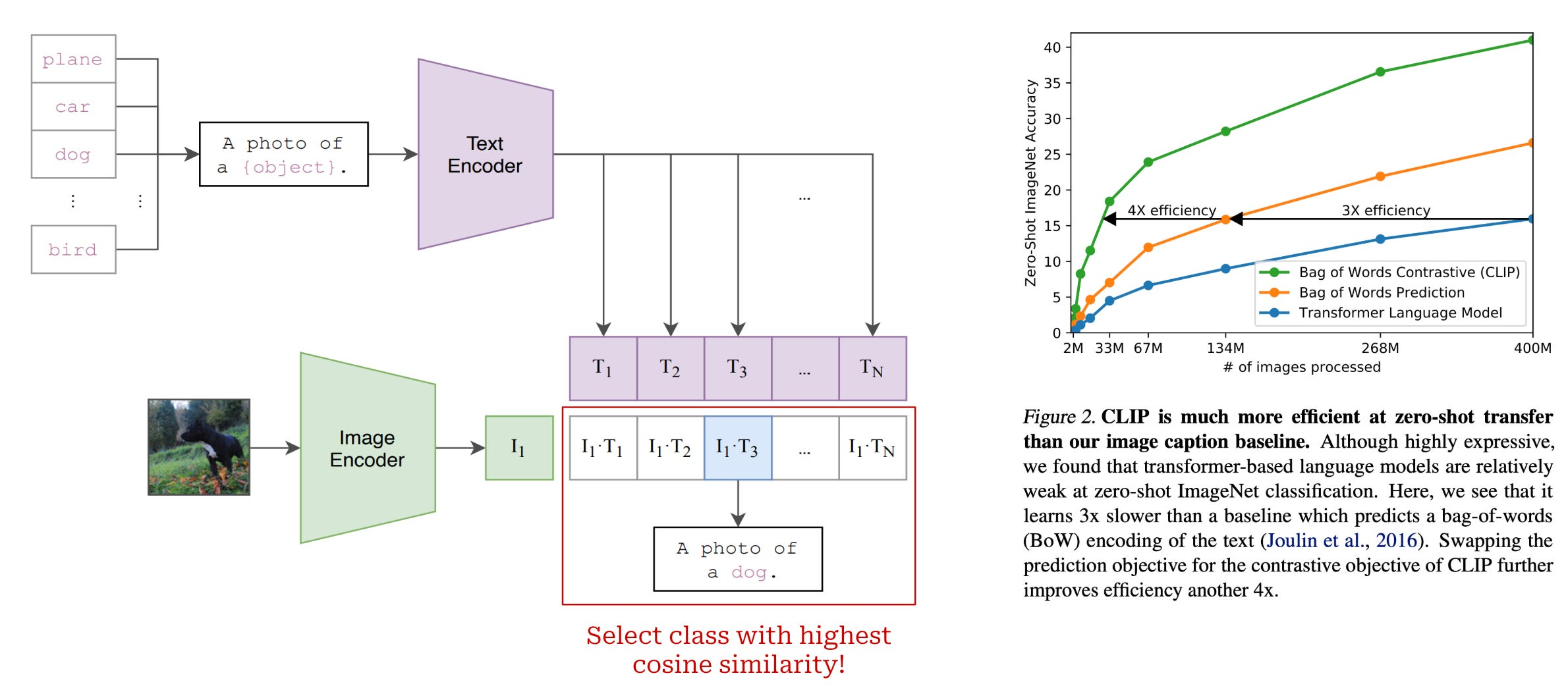
The key contribution of CLIP is not the model architecture, but rather the training objective. Using both an image and text encoder allows us to train the image encoder using the contrastive objective, making sure that the embeddings of images and texts that belong together are close to each other in embedding space, and images and text which don’t belong together are far apart. It also does not rely on large amounts of supervised data
SigLIP: a better CLIP Model#
The original CLIP model was trained with a softmax (cross-entropy loss) which requires a global view on all the pairwise similarities for normalization to probabilities. Researchers at Google found that one can replace this with a simpler sigmoid loss, which does not require this global-view. The task now simply because a binary one: does this image and text belong to each other, yes or no?
The sigmoid loss simultaneously allows further scaling up the batch size during pre-training (like 32k image-text pairs), while also performing better at smaller batch sizes. The model outperforms CLIP on both zero-shot image classification and image-text retrieval as shown below.
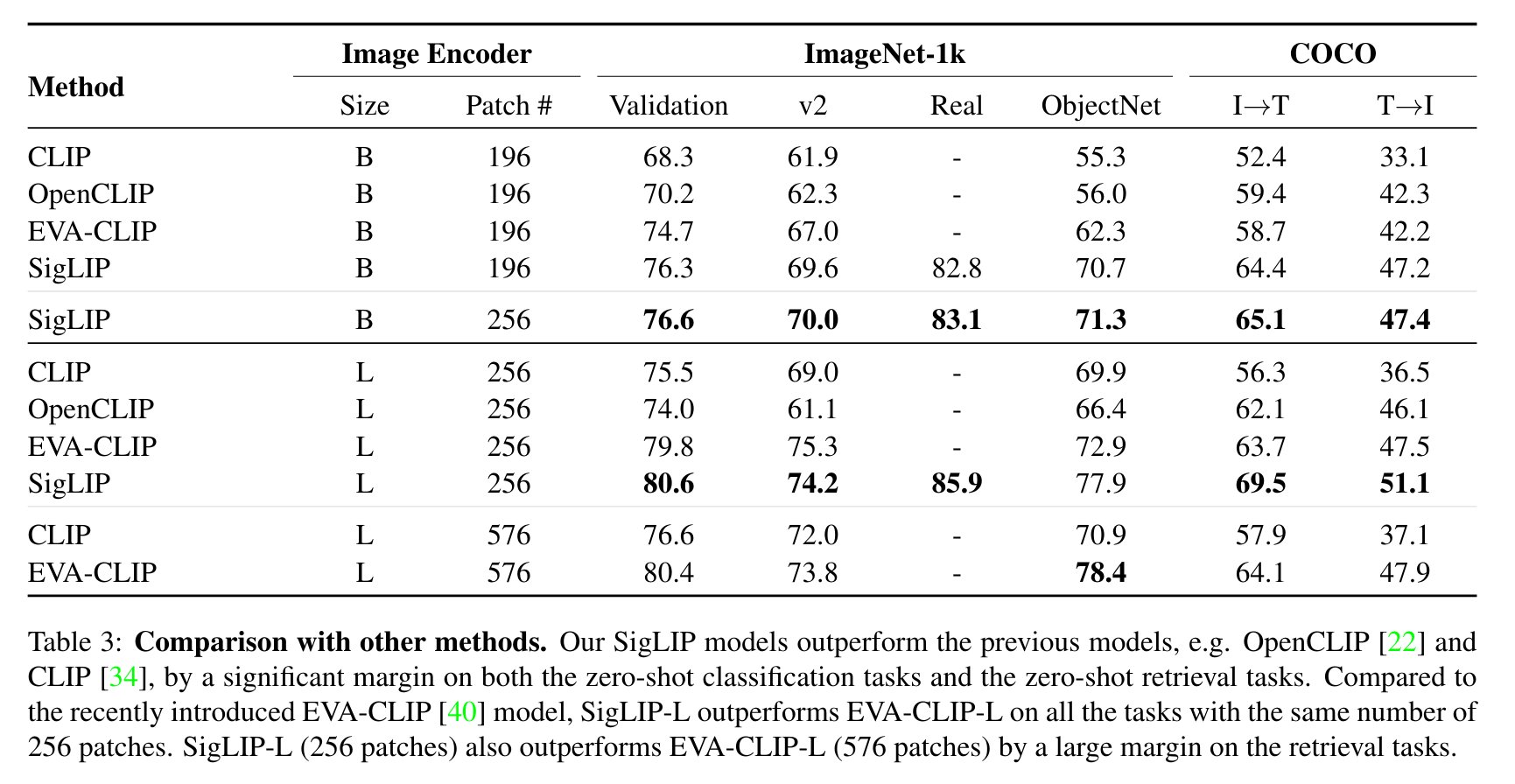
SigLIP docs: https://huggingface.co/docs/transformers/main/en/model_doc/siglip.
!pip install --upgrade -q git+https://github.com/huggingface/transformers sentencepiece protobuf torchvision
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
tensorflow 2.19.0 requires protobuf!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5,<6.0.0dev,>=3.20.3, but you have protobuf 6.33.1 which is incompatible.
[notice] A new release of pip is available: 24.0 -> 25.3
[notice] To update, run: pip install --upgrade pip
Load model#
Load a SigLIP model and its corresponding processor.
Note that the authors released several checkpoints, in “base”, “large” and “shape-optimized” versions.
Below we load the best English model, which has a “shape-optimized (so)” architecture, introduced in a paper prior to SigLIP. This model performs significantly better than a ViT-giant architecture while being a lot smaller.
Below we use the Auto API which automatically will load the right classes for us.
from transformers import AutoProcessor, SiglipModel
import torch
model_id = "google/siglip-so400m-patch14-384"
device = ("cuda" if torch.cuda.is_available() else "cpu")
processor = AutoProcessor.from_pretrained(model_id)
model = SiglipModel.from_pretrained(model_id).to(device).eval()
/Users/n0man/Code/n03an.me/.venv/lib/python3.12/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
WARNING:torchao.kernel.intmm:Warning: Detected no triton, on systems without Triton certain kernels will not work
W1118 06:54:46.383000 12715 torch/distributed/elastic/multiprocessing/redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Loading weights: 100%|██████████| 888/888 [00:00<00:00, 1421.11it/s, Materializing param=logit_bias]
model
SiglipModel(
(text_model): SiglipTextTransformer(
(embeddings): SiglipTextEmbeddings(
(token_embedding): Embedding(32000, 1152)
(position_embedding): Embedding(64, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(self_attn): SiglipAttention(
(k_proj): Linear(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear(in_features=1152, out_features=1152, bias=True)
(q_proj): Linear(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear(in_features=1152, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): GELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
)
)
)
(final_layer_norm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(head): Linear(in_features=1152, out_features=1152, bias=True)
)
(vision_model): SiglipVisionTransformer(
(embeddings): SiglipVisionEmbeddings(
(patch_embedding): Conv2d(3, 1152, kernel_size=(14, 14), stride=(14, 14), padding=valid)
(position_embedding): Embedding(729, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(self_attn): SiglipAttention(
(k_proj): Linear(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear(in_features=1152, out_features=1152, bias=True)
(q_proj): Linear(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear(in_features=1152, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): GELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
)
)
)
(post_layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(head): SiglipMultiheadAttentionPoolingHead(
(attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=1152, out_features=1152, bias=True)
)
(layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): GELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
)
)
)
SigLIP keeps CLIP’s dual‑tower design: a Transformer for text and a Vision Transformer (ViT) for images. Both towers produce L2‑normalized embeddings of the same dimensionality (here 1152). Instead of training with a global softmax over all pairwise similarities (as CLIP does), SigLIP uses a per‑pair sigmoid loss, which eliminates the need to form a large cross‑batch similarity matrix. This enables much larger batch sizes and more efficient scaling.
Text Tower: SiglipTextTransformer#
27-layer Transformer, 1152 hidden size, 4304-dim MLP intermediate, GELUTanh, token + positional embeddings, final projection head
Embeddings:
token_embedding: Embedding(32000, 1152)— Vocabulary size 32k (SentencePiece / subword tokens) mapped to 1152‑dim vectors.position_embedding: Embedding(64, 1152)— Fixed maximum sequence length of 64 tokens (paper constrains max text length to keep compute predictable).
Encoder:
27 stacked
SiglipEncoderLayerblocks (depth = 27). Each layer has:Pre‑norm pattern:
layer_norm1before self‑attention,layer_norm2before MLP.Self-attention projections:
q_proj,k_proj,v_proj,out_proj, each 1152→1152 (implying number of attention heads * head_dim sums to 1152).MLP:
fc1: 1152 → 4304,fc2: 4304 → 1152. Expansion ratio ≈ 3.73 (typical ViT uses 4; shape optimization may tune this ratio for parameter efficiency vs throughput).Activation:
GELUTanh()(a hybrid approximating GELU while possibly better behaved for large scale training).
Final normalization:
final_layer_normafter the stacked layers.Head: A linear projection (
head: Linear(1152 → 1152)) functioning as a final learned mapping (distinct from “CLS” usage; operates on pooled token representation—often the mean or first token depending on implementation).In SigLIP, the text embedding is derived from the transformed token sequence (with pooling logic in forward pass) then projected.
Vision Tower: SiglipVisionTransformer#
ViT-style patch embedding via Conv2d(kernel=14, stride=14) → 27-layer encoder → attention pooling head.
Embeddings:
patch_embedding: Conv2d(3, 1152, kernel_size=14, stride=14)— Implements patch extraction + linear projection in one convolution (standard ViT trick). With input resized so that width/height produce exactly 27 patches (27×27=729) -> matchesposition_embedding: Embedding(729, 1152).378 / 14 = 27 patches, so the model likely center‑crops or resizes to 378×378 to get 27 exact patches along each side (the “shape‑optimized” change reduces wasted pixels and mismatched padding).
Encoder:
Same depth: 27
SiglipEncoderLayerblocks mirroring the text architecture (shared structural design simplifies implementation and scaling).Each layer uses identical pattern: LN → MHSA → residual, LN → MLP → residual.
Post Layer Norm:
post_layernorm— Normalizes token embeddings after all encoder layers (preps them for pooling).Attention Pooling Head:
SiglipMultiheadAttentionPoolingHeadreplaces a simple CLS token: uses a Multihead Attention mechanism where a learnable query (or structured pooling queries) attends to all spatial patch tokens to produce an aggregated representation.This pooling head also has its own LayerNorm and MLP (again with GELUTanh and 1152→4304→1152) to refine the pooled vector.
Benefit vs CLS: Empirically better spatial summarization; can weigh informative regions more adaptively than a single positional token.
Scoring Mechanism#
both tower outputs L2-normalized vectors of dimension 1152…
Compute cosine similarity:
sim = image_embed · text_embed(embeds are L2-normalized).Apply learned temperature:
scaled = exp(logit_scale) * sim.Apply learned bias:
logit = scaled + logit_bias.Sigmoid:
p = sigmoid(logit)— independent probability that the pair matches (unlike softmax normalizing over all pairs)
Load Image and Text#
Input sample images
from PIL import Image
import io, base64
image0 = Image.open("../../_asset/vit/siglip/cats_remote.jpg")
image1 = Image.open("../../_asset/vit/siglip/hellokitty.jpg")
def to_b64(img: Image.Image, max_size=(140,140)):
img = img.copy()
img.thumbnail(max_size)
buf = io.BytesIO()
img.save(buf, format='JPEG')
img_b64 = base64.b64encode(buf.getvalue()).decode('utf-8')
return f"<img src='data:image/jpeg;base64,{img_b64}' style='width:{max_size[0]}px;height:auto;border-radius:4px;'/>"
print("input sample image 0:")
image0
input sample image 0:

print("input sample image 1:")
image1
input sample image 1:

Input Sample Texts
texts = ["tv remote, two sleeping cats", "a photo of 2 hamburgers", "hello kitty phone cover, girl holding phone"]
print("\n====input sample texts====")
for (idx, text) in enumerate(texts):
print(f"Text {idx}: {text}")
====input sample texts====
Text 0: tv remote, two sleeping cats
Text 1: a photo of 2 hamburgers
Text 2: hello kitty phone cover, girl holding phone
Generate input (text and image) tensors#
# important: we pass padding="max_length" as that's how the model was trained
inputs = processor(
text=texts,
images=[image0, image1],
return_tensors="pt",
padding="max_length"
).to(device)
print("\n===Input Shape===")
for k,v in inputs.items():
print(k,v.shape)
===Input Shape===
pixel_values torch.Size([2, 3, 384, 384])
input_ids torch.Size([3, 64])
Forward pass#
We perform a forward pass and get the logits_per_image. These indicate the unnormalized scores for each image-text pair.
As SigLIP has been trained using the sigmoid loss (rather than cross-entropy as with CLIP), we need to apply the sigmoid activation function on the logits to turn them into individual probabilities (unlike CLIP, where probabilities sum to 1).
Note: the probabilities of SigLIP need to be interpreted independently. They are a lot flatter compared to CLIP. Refer to this thread for more info.
import torch, io, base64
from PIL import Image
# Forward pass for both images & all texts
with torch.no_grad():
outputs = model(**inputs)
# SigLIP returns a dataclass-like object with several fields.
# We'll inspect the main ones relevant for retrieval and similarity.
logits_per_image = outputs.logits_per_image # (num_images, num_texts)
logits_per_text = outputs.logits_per_text # (num_texts, num_images) reciprocal view
image_embeds = outputs.image_embeds # (num_images, dim) normalized
text_embeds = outputs.text_embeds # (num_texts, dim) normalized
print("=== Output Component Shapes ===")
print(f"logits_per_image: {logits_per_image.shape} (scores: image_i vs text_j)")
print(f"logits_per_text: {logits_per_text.shape} (scores: text_j vs image_i)")
print(f"image_embeds: {image_embeds.shape} (L2-normalized image vectors)")
print(f"text_embeds: {text_embeds.shape} (L2-normalized text vectors)")
=== Output Component Shapes ===
logits_per_image: torch.Size([2, 3]) (scores: image_i vs text_j)
logits_per_text: torch.Size([3, 2]) (scores: text_j vs image_i)
image_embeds: torch.Size([2, 1152]) (L2-normalized image vectors)
text_embeds: torch.Size([3, 1152]) (L2-normalized text vectors)
Output tensors after forward pass#
The forward pass of SiglipModel returns a structured output object (a dataclass) with several key tensors
logits_per_image: Shape(num_images, num_texts). Each entry[i, j]is the scaled + biased logit score indicating how well image i matches text j. Applysigmoidfor an independent probability per pair.logits_per_text: Shape(num_texts, num_images). Transposed perspective: score of text j against image i. Ranking either tensor yields the same ordering per pair.image_embeds: Shape(num_images, dim). L2-normalized projected image embeddings. Cosine similarity between an image and a text embedding equals their dot product.text_embeds: Shape(num_texts, dim). L2-normalized projected text embeddings.
⭕ Using Logits per image to compute sigmoid probabilities#
logits_per_image: Shape (num_images, num_texts). Each entry [i, j] is the scaled + biased logit score indicating how well image i matches text j. Apply sigmoid for an independent probability per pair.
from IPython.display import HTML
# Convert logits_per_image to independent sigmoid probabilities
probs = torch.sigmoid(logits_per_image)
print("\n=== Example probabilities for image 0 ===")
display(HTML(to_b64(image0)))
for j, t in enumerate(texts):
print(f"P(match|image0,'{t}'): {probs[0,j]*100:.2f}%")
print("\n=== Example probabilities for image 1 ===")
display(HTML(to_b64(image1)))
for j, t in enumerate(texts):
print(f"P(match|image1,'{t}'): {probs[1,j]*100:.2f}%")
=== Example probabilities for image 0 ===

P(match|image0,'tv remote, two sleeping cats'): 99.98%
P(match|image0,'a photo of 2 hamburgers'): 0.00%
P(match|image0,'hello kitty phone cover, girl holding phone'): 0.00%
=== Example probabilities for image 1 ===

P(match|image1,'tv remote, two sleeping cats'): 0.00%
P(match|image1,'a photo of 2 hamburgers'): 0.00%
P(match|image1,'hello kitty phone cover, girl holding phone'): 100.00%
tabular form
images = [image0, image1]
thumbs = [to_b64(im.convert('RGB')) for im in images]
# Build simple HTML table
header = ['Image'] + texts
rows = []
for i, (b64, row_probs) in enumerate(zip(thumbs, probs)):
img_tag = to_b64(images[i])
cells = [f"<td style='border:1px solid #ccc;padding:6px;text-align:center;vertical-align:middle;'>{img_tag}<div style='font-size:11px;color:#555;margin-top:4px;'>image {i}</div></td>"]
for p in row_probs.tolist():
cells.append(f"<td style='border:1px solid #ccc;padding:6px;text-align:right;font-family:monospace;'>{p*100:.2f}%</td>")
rows.append('<tr>' + ''.join(cells) + '</tr>')
html = ["<table style='border-collapse:collapse;margin:8px 0;'>", '<tr>' + ''.join(f"<th style='border:1px solid #ccc;padding:6px;background:black;color:white;'>" + h + '</th>' for h in header) + '</tr>'] + rows + ["</table>"]
html.append("<p style='font-size:12px;color:#555;'>Each cell shows sigmoid(image,text) as an independent probability. Rows are images; columns are candidate texts.</p>")
display(HTML('\n'.join(html)))
| Image | tv remote, two sleeping cats | a photo of 2 hamburgers | hello kitty phone cover, girl holding phone |
|---|---|---|---|
image 0 | 99.98% | 0.00% | 0.00% |
image 1 | 0.00% | 0.00% | 100.00% |
Each cell shows sigmoid(image,text) as an independent probability. Rows are images; columns are candidate texts.
⭕ Using image and text embeddings to compute sigmoid probabilities#
“GIVEN” L2-normalized projected image and text embeddings- “THE” Cosine similarity between an image and a text embedding equals their dot product.
Compute cosine similarity:
cos = image_embeds[i] · text_embeds[j](since both normalized).Apply learned temperature:
scaled = exp(logit_scale) * cos.Add learned bias:
logit = scaled + logit_bias.Independent probability:
prob = sigmoid(logit)(does not sum to 1 across texts).Relative distribution (optional):
softmax(logits_per_image[i])over candidate texts for image i.
imp notes…
A uniform additive bias shifts all logits equally; ranking by cosine, scaled logits, or biased logits yields the same order.
Very large
exp(logit_scale)stretches the cosine range so that the sigmoid operates in a steeper, informative region.
cos = image_embeds[0] @ text_embeds[0] # cosine similarity via dot product (both are L2-normalized)
scaled_logit = model.logit_scale.exp() * cos
biased_logit = scaled_logit + model.logit_bias
prob = torch.sigmoid(biased_logit)
display(HTML(to_b64(image0)))
print(f"Probability for Image 0 and Text 0 \"{texts[0]}\": {prob[0]*100:.2f}%")
Probability for Image 0 and Text 0 "tv remote, two sleeping cats": 99.98%
cos = image_embeds[1] @ text_embeds[2] # cosine similarity via dot product (both are L2-normalized)
scaled_logit = model.logit_scale.exp() * cos
biased_logit = scaled_logit + model.logit_bias
prob = torch.sigmoid(biased_logit)
display(HTML(to_b64(image1)))
print(f"Probability for Image 1 and Text 2 \"{texts[2]}\": {prob[0]*100:.2f}%")
Probability for Image 1 and Text 2 "hello kitty phone cover, girl holding phone": 100.00%
SigLIP Retrieval Pipelien using Multimodal search#
Using the above concepts, we will ingest all the image embeddings and then accept input text as user query to compute similarity and show probability match…
from typing import List, Dict
import torch
from PIL import Image
import torch.nn.functional as F
class SiglipRetriever:
def __init__(self, model, processor, device):
self.device = device
self.processor = processor
self.model = model
@torch.inference_mode()
def image_emb(self, image: Image.Image):
inputs = self.processor(images=image, text=[""], return_tensors="pt", padding="max_length").to(self.device)
out = self.model(**inputs)
return out.image_embeds[0] # normalized
@torch.inference_mode()
def text_emb(self, texts: List[str]):
dummy = Image.new("RGB", (224, 224), color=(0, 0, 0))
inputs = self.processor(images=dummy, text=texts, return_tensors="pt", padding="max_length").to(self.device)
out = self.model(**inputs)
return out.text_embeds # (B, D) normalized
@torch.inference_mode()
def search(self, query: str, image_matrix: torch.Tensor, meta: List[Dict], k=5):
q = self.text_emb([query])[0] # (D,)
cos = (image_matrix @ q) # cosine similarities (N,)
logit_scale = self.model.logit_scale.exp()
logit_bias = self.model.logit_bias # scalar parameter
logits_no_bias = logit_scale * cos
logits = logits_no_bias + logit_bias # match forward()
vals, idxs = torch.topk(logits, k=min(k, logits.shape[0]))
probs = torch.sigmoid(vals)
return [
{
"logit": float(v), # scaled + bias (official)
"logit_no_bias": float(logits_no_bias[i]),
"cosine": float(cos[i]),
"prob_percent": float(p * 100),
**meta[i],
}
for v, p, i in zip(vals.tolist(), probs.tolist(), idxs.tolist())
]
Create image embeddings#
from PIL import Image
import torch
retriever = SiglipRetriever(model, processor, device)
image_sources = {
"one": "../../_asset/vit/siglip/cats_remote.jpg",
"two": "../../_asset/vit/siglip/hellokitty.jpg",
}
emb_list = []
vector_db = []
for p in image_sources.values():
image = Image.open(p).convert("RGB")
emb = retriever.image_emb(image)
emb_list.append(emb)
vector_db.append({"path": p, "image": image, "embedding": emb})
images_emb = torch.stack(emb_list) # (N, D)
images_emb.shape
torch.Size([2, 1152])
Helper function to dispay results and user query
def display_search_results(results, query):
print(f"=== Search Results for query: '{query}' ===>")
for r in results:
display(HTML(to_b64(r['image'])))
print(f"Path: {r['path']}")
print(f" Logit: {r['logit']:.4f} (no bias: {r['logit_no_bias']:.4f})")
print(f" Cosine similarity: {r['cosine']:.4f}")
print(f" Probability: {r['prob_percent']:.2f}%")
print()
Test Run - probe query #1#
Lets test the sensitivity of image and text pair
query = "tv remote, sleeping cats"
results = retriever.search(query, images_emb, vector_db, k=len(vector_db))
display_search_results(results, query)
=== Search Results for query: 'tv remote, sleeping cats' ===>
Path: ../../_asset/vit/siglip/cats_remote.jpg
Logit: 8.8806 (no bias: 25.4270)
Cosine similarity: 0.2264
Probability: 99.99%
Path: ../../_asset/vit/siglip/hellokitty.jpg
Logit: -15.2638 (no bias: 1.2827)
Cosine similarity: 0.0114
Probability: 0.00%
tyring subset of the query with main objects such as cats
query = "2 sleeping cats"
results = retriever.search(query, images_emb, vector_db, k=len(vector_db))
display_search_results(results, query)
=== Search Results for query: '2 sleeping cats' ===>
Path: ../../_asset/vit/siglip/cats_remote.jpg
Logit: 1.6523 (no bias: 18.1988)
Cosine similarity: 0.1620
Probability: 83.92%
Path: ../../_asset/vit/siglip/hellokitty.jpg
Logit: -20.4068 (no bias: -3.8603)
Cosine similarity: -0.0344
Probability: 0.00%
Using text ‘two’ instead of number 2
query = "two cats"
results = retriever.search(query, images_emb, vector_db, k=len(vector_db))
display_search_results(results, query)
=== Search Results for query: 'two cats' ===>
Path: ../../_asset/vit/siglip/cats_remote.jpg
Logit: -0.2868 (no bias: 16.2597)
Cosine similarity: 0.1447
Probability: 42.88%
Path: ../../_asset/vit/siglip/hellokitty.jpg
Logit: -13.0582 (no bias: 3.4882)
Cosine similarity: 0.0311
Probability: 0.00%
generalizing instead of specific query
query = "some cats"
results = retriever.search(query, images_emb, vector_db, k=len(vector_db))
display_search_results(results, query)
=== Search Results for query: 'some cats' ===>
Path: ../../_asset/vit/siglip/cats_remote.jpg
Logit: -2.9780 (no bias: 13.5684)
Cosine similarity: 0.1208
Probability: 4.84%
Path: ../../_asset/vit/siglip/hellokitty.jpg
Logit: -11.2014 (no bias: 5.3450)
Cosine similarity: 0.0476
Probability: 0.00%
tyring with sub objects such as tv remote
query = "tv remote"
results = retriever.search(query, images_emb, vector_db, k=len(vector_db))
display_search_results(results, query)
=== Search Results for query: 'tv remote' ===>
Path: ../../_asset/vit/siglip/cats_remote.jpg
Logit: -8.4682 (no bias: 8.0782)
Cosine similarity: 0.0719
Probability: 0.02%
Path: ../../_asset/vit/siglip/hellokitty.jpg
Logit: -14.1337 (no bias: 2.4127)
Cosine similarity: 0.0215
Probability: 0.00%
Test run - Probe query #2#
query = "hello kitty phone cover, women holding phone"
results = retriever.search(query, images_emb, vector_db, k=len(vector_db))
display_search_results(results, query)
=== Search Results for query: 'hello kitty phone cover, women holding phone' ===>
Path: ../../_asset/vit/siglip/hellokitty.jpg
Logit: 9.9590 (no bias: 26.5054)
Cosine similarity: 0.2360
Probability: 100.00%
Path: ../../_asset/vit/siglip/cats_remote.jpg
Logit: -16.6330 (no bias: -0.0866)
Cosine similarity: -0.0008
Probability: 0.00%
query attributes of sub object such as hello kitty
query = "hello kitty, asian women"
results = retriever.search(query, images_emb, vector_db, k=len(vector_db))
display_search_results(results, query)
=== Search Results for query: 'hello kitty, asian women' ===>
Path: ../../_asset/vit/siglip/hellokitty.jpg
Logit: 5.9333 (no bias: 22.4797)
Cosine similarity: 0.2001
Probability: 99.74%
Path: ../../_asset/vit/siglip/cats_remote.jpg
Logit: -11.2319 (no bias: 5.3145)
Cosine similarity: 0.0473
Probability: 0.00%
query = "hello kitty"
results = retriever.search(query, images_emb, vector_db, k=len(vector_db))
display_search_results(results, query)
=== Search Results for query: 'hello kitty' ===>
Path: ../../_asset/vit/siglip/hellokitty.jpg
Logit: -0.6144 (no bias: 15.9320)
Cosine similarity: 0.1418
Probability: 35.11%
Path: ../../_asset/vit/siglip/cats_remote.jpg
Logit: -8.3552 (no bias: 8.1913)
Cosine similarity: 0.0729
Probability: 0.02%
Finally, lets try Image to Image search#
import torch
from PIL import Image
@torch.inference_mode()
def image_to_image_search(p_img, corpus_embs, k=10):
q = retriever.image_emb(p_img)
sims = corpus_embs @ q # (N,)
vals, idxs = torch.topk(sims, k=min(k, sims.shape[0]))
return [(int(i), float(v)) for v, i in zip(vals.tolist(), idxs.tolist())]
probe_path = "../../_asset/vit/siglip/cat_probe.jpg" # change path if needed
probe_image = Image.open(probe_path).convert("RGB")
results = image_to_image_search(probe_image, images_emb)
results
[(0, 0.7647855281829834), (1, 0.39073675870895386)]
print("===Probe Image====")
probe_image
===Probe Image====

print("===Matched Image====")
print(f"Probability: {results[0][1]*100:.2f}%")
images[results[0][0]]
===Matched Image====
Probability: 76.48%

Trying more realistic images for zero shot test#
Lets look at how global embedding dilutes smaller objects (objects that are not dominant)…
from PIL import Image
import torch
retriever = SiglipRetriever(model, processor, device)
image_sources = {
# "one": "../../_asset/vit/siglip/hanging_jacket.jpg",
"two": "../../_asset/vit/siglip/umbrella.jpg",
"two_crop": "../../_asset/vit/siglip/umbrella_crop.jpg",
"three": "../../_asset/vit/siglip/nike.jpg",
"three_crop": "../../_asset/vit/siglip/nike_crop.jpg",
}
emb_list = []
vector_db = []
for p in image_sources.values():
image = Image.open(p).convert("RGB")
print(f"Indexing image from path: {p}")
display(HTML(to_b64(image, max_size=(600,600))))
emb = retriever.image_emb(image)
emb_list.append(emb)
vector_db.append({"path": p, "image": image, "embedding": emb})
images_emb = torch.stack(emb_list) # (N, D)
images_emb.shape
Indexing image from path: ../../_asset/vit/siglip/umbrella.jpg

Indexing image from path: ../../_asset/vit/siglip/umbrella_crop.jpg

Indexing image from path: ../../_asset/vit/siglip/nike.jpg

Indexing image from path: ../../_asset/vit/siglip/nike_crop.jpg

torch.Size([4, 1152])
query = "white umbrella and hanging bags"
results = retriever.search(query, images_emb, vector_db, k=len(vector_db))
display_search_results(results, query)
=== Search Results for query: 'white umbrella and hanging bags' ===>

Path: ../../_asset/vit/siglip/umbrella_crop.jpg
Logit: 5.1610 (no bias: 21.7074)
Cosine similarity: 0.1932
Probability: 99.43%

Path: ../../_asset/vit/siglip/nike.jpg
Logit: -9.4913 (no bias: 7.0551)
Cosine similarity: 0.0628
Probability: 0.01%

Path: ../../_asset/vit/siglip/umbrella.jpg
Logit: -9.6137 (no bias: 6.9327)
Cosine similarity: 0.0617
Probability: 0.01%

Path: ../../_asset/vit/siglip/nike_crop.jpg
Logit: -13.0417 (no bias: 3.5048)
Cosine similarity: 0.0312
Probability: 0.00%
query = "man with nike bag"
results = retriever.search(query, images_emb, vector_db, k=len(vector_db))
display_search_results(results, query)
=== Search Results for query: 'man with nike bag' ===>
Path: ../../_asset/vit/siglip/nike_crop.jpg
Logit: 8.2631 (no bias: 24.8096)
Cosine similarity: 0.2209
Probability: 99.97%
Path: ../../_asset/vit/siglip/nike.jpg
Logit: -3.2109 (no bias: 13.3355)
Cosine similarity: 0.1187
Probability: 3.88%
Path: ../../_asset/vit/siglip/umbrella_crop.jpg
Logit: -9.3905 (no bias: 7.1560)
Cosine similarity: 0.0637
Probability: 0.01%
Path: ../../_asset/vit/siglip/umbrella.jpg
Logit: -13.1334 (no bias: 3.4130)
Cosine similarity: 0.0304
Probability: 0.00%