◉ VeRi: Vehicle Re-identification#


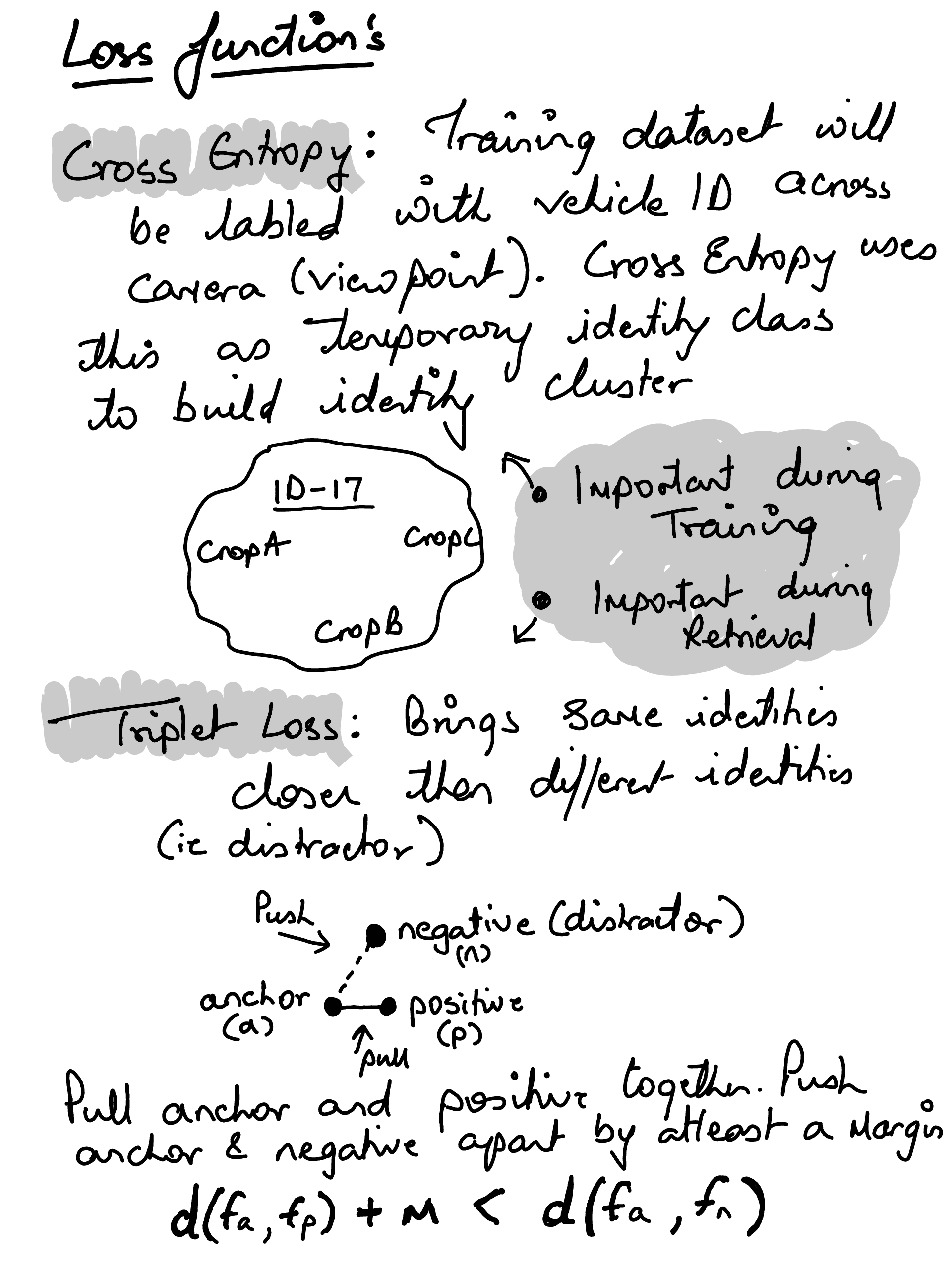

VeRi-776 Dataset#
The VeRi dataseat contains over 50,000 images of 776 vehicles captured by 20 cameras covering an 1.0 km^2 area in 24 hours (Yongtai Point china). Each vehicle is captured by 2 ∼ 18 cameras in different viewpoints, illuminations, resolutions, and occlusions.
There are 2 key files that will be used for evals (query)
Ground Truth (gt_index.txt): These reference images of the same vehicle ID captured by different cameras than the query image. These are the “correct” matches your model is supposed to find.
Junk (jk_index.txt): These are images of the same vehicle ID captured by the same camera as the query image
Role of JK index: Re-ID tasks, the goal is to track an object across different locations. Matching an image to another image from the same camera is considered too easy or redundant.
[TODO] 🚧🚧🚧 Explore VERI-Wild next#
from helper import *
VERI_ROOT = Path("/home/n03an/Downloads/VeRi")
IMAGE_TRAIN_DIR = VERI_ROOT / "image_train"
IMAGE_QUERY_DIR = VERI_ROOT / "image_query"
IMAGE_TEST_DIR = VERI_ROOT / "image_test"
NAME_TRAIN_TXT = VERI_ROOT / "name_train.txt"
NAME_QUERY_TXT = VERI_ROOT / "name_query.txt"
NAME_TEST_TXT = VERI_ROOT / "name_test.txt"
TRAIN_LABEL_XML = VERI_ROOT / "train_label.xml"
TEST_LABEL_XML = VERI_ROOT / "test_label.xml"
GT_IMAGE_TXT = VERI_ROOT / "gt_index.txt"
JK_IMAGE_TXT = VERI_ROOT / "jk_index.txt"
VeRi: download#
have following categories of files and folders
Training#
image_train/. This dir contains 37746 images for trainingname_train.txt. It lists all 37746 train file (img) names. e.g.
0769_c017_00075060_0.jpg
0769_c017_00075070_0.jpg
0769_c019_00075205_0.jpg
0769_c019_00075220_0.jpg
train_label.xml. It lists the labels, e.g., vehicle ID, camera ID, color, type, of the training images. e.g.
<Item imageName="0769_c017_00075060_0.jpg" vehicleID="0769" cameraID="c017" colorID="10" typeID="1" />
<Item imageName="0769_c017_00075070_0.jpg" vehicleID="0769" cameraID="c017" colorID="10" typeID="1" />
<Item imageName="0769_c019_00075205_0.jpg" vehicleID="0769" cameraID="c019" colorID="10" typeID="1" />
Testing#
image_test/. This dir contains 11579 images for testingname_test.txt. It lists all test file names (11579)test_label.xml. It lists the labels of all test images
Evals#
name_query.txt. It lists 1678 image names that will be used for quering during Evals. Consider this as the probe image taken from given camera IDgt_image.txt. Have 1678 entries where each line shows the ground truths of respective query image fromname_query.txton the same line (index). e.g. line 77 ingt_index.txtwould have entry520 521 522that would represent gound truth for image0042_c011_00086255_0.jpginname_query.txton line 77.520 521 522are basically indices (line numbers) pointing to test names datasetname_test.txtjk_image.txt: follows similar protocol to gt_image.txt, just that each line represents reference to images of the same vehicle ID captured by the same camera. Basically we want our model to get better in re-identifying same vehicle from other camera rather than the same camera.
During testing, junk images would be ignored… they are neither counted as “true positives” nor “false positives”
Parse VeRi datasets (XML and txt)#
train_meta = parse_veri_xml(TRAIN_LABEL_XML)
test_meta = parse_veri_xml(TEST_LABEL_XML)
train_names = read_name_list(NAME_TRAIN_TXT)
query_names = read_name_list(NAME_QUERY_TXT)
test_names = read_name_list(NAME_TEST_TXT)
print("training------")
print("Train Labels from train_label.xml:", len(train_meta))
print("Train names from train_name.txt:", len(train_names))
print("testing------")
print("Test Labels from test_label.xml:", len(test_meta))
print("Test names from test_name.txt:", len(test_names))
print("Evals------")
print("Query names from query_name.txt:", len(query_names))
training------
Train Labels from train_label.xml: 37746
Train names from train_name.txt: 37746
testing------
Test Labels from test_label.xml: 11579
Test names from test_name.txt: 11579
Evals------
Query names from query_name.txt: 1678
Parse VeRi evals datasets (Ground truth and Junk)#
gt_idx_map = parse_per_query_index_lists(
VERI_ROOT / "gt_index.txt",
query_names,
test_names,
)
jk_idx_map = parse_per_query_index_lists(
VERI_ROOT / "jk_index.txt",
query_names,
test_names,
)
sample_q = query_names[50]
print("Sample Eval query:", sample_q)
print("Ground Truth count:", len(gt_idx_map[sample_q]))
print("Junk Images count:", len(jk_idx_map[sample_q]))
Sample Eval query: 0030_c008_00049770_0.jpg
Ground Truth count: 22
Junk Images count: 12
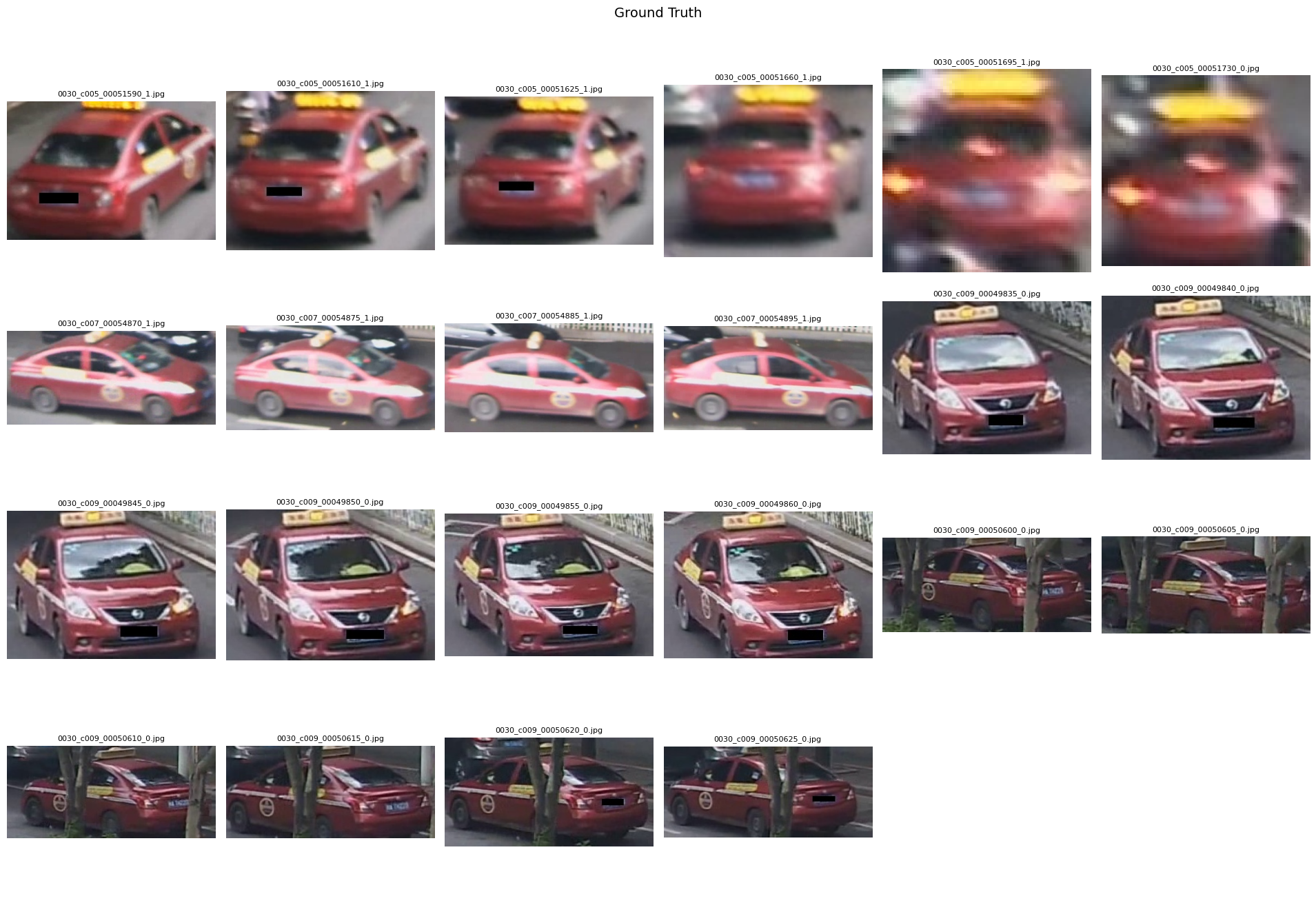
show_images_grid([sample_q], IMAGE_QUERY_DIR, title="Query (Probe Image)", cols=1, figsize_per_cell=(5, 5))
gt_names = [test_names[i] for i in sorted(gt_idx_map[sample_q])]
show_images_grid(gt_names, IMAGE_TEST_DIR, title="Ground Truth", cols=6)
jk_names = [test_names[i] for i in sorted(jk_idx_map[sample_q])]
show_images_grid(jk_names, IMAGE_TEST_DIR, title="Taken from Probe Image Camera (should be ignored)", cols=6)


Hyperparameters#
SEED = 42
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
IMG_H, IMG_W = 256, 256
P, K = 16, 4
BATCH_SIZE = P * K
EPOCHS = 100
NUM_WORKERS = 4
EVAL_EVERY = 5
LR = 3e-4
WEIGHT_DECAY = 5e-4
LABEL_SMOOTHING = 0.1
TRIPLET_MARGIN = 0.3
# Loss weights
W_ID = 1.0
W_TRI = 1.0
# W_COLOR = 0.1
# W_TYPE = 0.1
EARLY_STOP_PATIENCE_EVALS = 3
EARLY_STOP_MIN_DELTA = 0.001 #only count as improvement if mAP increases by at least 0.001
# AIN = Instance Normalization (Adaptive/Instance-Norm style blocks in the network)
# best_v2 with mAP 0.6928
# MODEL_NAME = "osnet_ain_x1_0"
# Baseline
MODEL_NAME = "osnet_x1_0"
def set_seed(seed=SEED):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
set_seed()
print(f"Using device: {DEVICE}")
Using device: cuda
Dataset and Eval class#
class VeRiTrainDataset prepares VeRi training data for learning vehicle re-identification (ReID)
class VeRiTrainDataset(Dataset):
def __init__(self, image_dir, names, meta, transform=None):
self.image_dir = Path(image_dir)
self.transform = transform
samples = []
for name in names:
if name not in meta:
continue
info = meta[name]
pid = info["pid"]
camid = info["camid"]
if pid is None or pid < 0:
continue
samples.append((name, pid, camid))
# Relabeling to Contiguous Indices
# Why? Raw IDs may be sparse (e.g., [5, 12, 99]). Neural network classifiers need contiguous labels [0, 1, 2].
unique_pids = sorted(set(pid for _, pid, _ in samples))
self.pid2label = {pid: i for i, pid in enumerate(unique_pids)}
self.samples = []
for name, pid, camid in samples:
self.samples.append((name, self.pid2label[pid], camid))
self.num_ids = len(self.pid2label)
print(f"[Training Dataset Init] samples={len(self.samples)} | Unique Vehicles={self.num_ids}")
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
img_name, pid, camid = self.samples[idx]
img_path = self.image_dir / img_name
img = Image.open(img_path).convert("RGB")
if self.transform:
img = self.transform(img)
return img, pid, camid, str(img_path)
This dataset class for VeRi query and test (gallery) images for evaluation…
class VeRiEvalDataset(Dataset):
def __init__(self, image_dir, names, meta, transform=None):
self.image_dir = Path(image_dir)
self.transform = transform
self.samples = []
for name in names:
if name not in meta:
continue
info = meta[name]
self.samples.append((name, info["pid"], info["camid"]))
# Verify no samples were skipped (important for index-based eval)
if len(self.samples) != len(names):
print(f"[Warning] {len(names) - len(self.samples)} images skipped due to missing metadata")
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
img_name, pid, camid = self.samples[idx]
img_path = self.image_dir / img_name
img = Image.open(img_path).convert("RGB")
if self.transform:
img = self.transform(img)
return img, pid, camid, img_name # img_name is important for official protocol eval
P×K batch sampler for triplet/metric learning… it ensures each batch contains exactly P (num_pids_per_batch) identities with K (num_instances) instances each.
P, K = 16, 4
BATCH_SIZE = P * K
class PKBatchSampler(Sampler):
def __init__(self, data_source, num_pids_per_batch, num_instances):
self.data_source = data_source
self.num_pids_per_batch = num_pids_per_batch
self.num_instances = num_instances
self.index_dic = defaultdict(list)
# all dataset indices grouped by vehicle ID.
# e.g. {pid: [idx1, idx2, idx3, ...]}
for index, sample in enumerate(data_source.samples):
pid = sample[1] # (name, pid, camid)
self.index_dic[pid].append(index)
self.pids = list(self.index_dic.keys())
def __iter__(self):
batch_idxs_dict = defaultdict(list)
# prepare chunks per PID
for pid in self.pids:
idxs = self.index_dic[pid].copy()
# If a vehicle has fewer than K images, oversample with replacement
# Shuffle indices and split into chunks of size K
if len(idxs) < self.num_instances:
idxs = np.random.choice(idxs, size=self.num_instances, replace=True).tolist()
random.shuffle(idxs)
chunk = []
for idx in idxs:
chunk.append(idx)
if len(chunk) == self.num_instances:
batch_idxs_dict[pid].append(chunk)
chunk = []
avai_pids = self.pids.copy()
final_idxs = []
# Assemble batches...
# - randomly select P vehicle IDs
# - take one chunk of K images for each
# - remove PID from the pool when exhausted (no more chunks)
while len(avai_pids) >= self.num_pids_per_batch:
selected = random.sample(avai_pids, self.num_pids_per_batch)
for pid in selected:
batch = batch_idxs_dict[pid].pop(0)
final_idxs.extend(batch)
if len(batch_idxs_dict[pid]) == 0:
avai_pids.remove(pid)
return iter(final_idxs)
def __len__(self):
return len(self.data_source)
Transform pipelines (training and testing)#
def build_transforms(img_h=256, img_w=256):
# These are ImageNet normalization statistics (RGB mean and std)
# values computed across millions of ImageNet images
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
train_tfms = T.Compose([
T.Resize((img_h, img_w)),
T.RandomHorizontalFlip(0.5),
T.Pad(10),
T.RandomCrop((img_h, img_w)),
T.ColorJitter(brightness=0.15, contrast=0.15, saturation=0.1, hue=0.02),
T.ToTensor(),
T.Normalize(mean, std),
T.RandomErasing(p=0.4, value='random')
])
test_tfms = T.Compose([
T.Resize((img_h, img_w)),
T.ToTensor(),
T.Normalize(mean, std),
])
return train_tfms, test_tfms
setup the pipeline for training
train_tfmsand evaluationtest_tfmsCreate Datasets
train_ds: Training with labels
query_ds: Probe images for eval
gallery_ds: Search gallery (test set) for eval
train_tfms, test_tfms = build_transforms(IMG_H, IMG_W)
train_ds = VeRiTrainDataset(
image_dir=IMAGE_TRAIN_DIR,
names=train_names,
meta=train_meta,
transform=train_tfms
)
query_ds = VeRiEvalDataset(IMAGE_QUERY_DIR, query_names, test_meta, transform=test_tfms)
gallery_ds = VeRiEvalDataset(IMAGE_TEST_DIR, test_names, test_meta, transform=test_tfms)
train_sampler = PKBatchSampler(train_ds, num_pids_per_batch=P, num_instances=K)
train_loader = DataLoader(
train_ds,
batch_size=BATCH_SIZE,
sampler=train_sampler,
num_workers=NUM_WORKERS,
pin_memory=True,
drop_last=True
)
query_loader = DataLoader(
query_ds,
batch_size=128,
shuffle=False,
num_workers=NUM_WORKERS,
pin_memory=True
)
gallery_loader = DataLoader(
gallery_ds,
batch_size=128,
shuffle=False,
num_workers=NUM_WORKERS,
pin_memory=True
)
num_train_ids = train_ds.num_ids
print("Train images:", len(train_ds))
print("Train IDs:", num_train_ids)
print("Queries:", len(query_ds))
print("Gallery (Test set):", len(gallery_ds))
[Training Dataset Init] samples=37746 | Unique Vehicles=575
Train images: 37746
Train IDs: 575
Queries: 1678
Gallery (Test set): 11579
Model Class (OSNetReID)#
Forward pass
Input Image [B, 3, 256, 256]
OSNet backbone (pretrained imagenet) gives
Feature Maps [B, 512, 8, 8]Global Avg Pool (F.adaptive_avg_pool2d) gives
Features [B, 512]for triplet loss + retrievalBatchNorm (Normalization for stability)
Heads
ID Head
class OSNetReID(nn.Module):
def __init__(
self,
num_ids,
model_name="osnet_ain_x1_0",
pretrained=True,
feat_dim_override=None
):
super().__init__()
self.backbone = torchreid.models.build_model(
name=model_name,
num_classes=num_ids, # required by builder, but we won't rely on its classifier
pretrained=pretrained, # ImageNet weights
use_gpu=torch.cuda.is_available()
)
# Infer feature dim by a dummy forward through featuremaps
# OSNet x1.0 is usually 512 channels at final stage, but let's infer safely.
if feat_dim_override is None:
with torch.no_grad():
dummy = torch.zeros(1, 3, IMG_H, IMG_W)
if hasattr(self.backbone, "featuremaps"):
fm = self.backbone.featuremaps(dummy)
feat_dim = fm.shape[1]
else:
feat_dim = 512
else:
feat_dim = feat_dim_override
self.feat_dim = feat_dim
# Optional embedding bottleneck (helps stability)
self.bn = nn.BatchNorm1d(feat_dim)
self.bn.bias.requires_grad_(False)
# Heads
self.id_head = nn.Linear(feat_dim, num_ids)
# Added these aux heads but then it was hurting more than helping
# self.color_head = nn.Linear(feat_dim, num_colors)
# self.type_head = nn.Linear(feat_dim, num_types)
def forward(self, x):
if hasattr(self.backbone, "featuremaps"):
fm = self.backbone.featuremaps(x)
feats = F.adaptive_avg_pool2d(fm, 1).view(fm.size(0), -1)
else:
feats = self.backbone(x)
feats_bn = self.bn(feats)
logits_id = self.id_head(feats_bn)
# logits_color = self.color_head(feats_bn)
# logits_type = self.type_head(feats_bn)
return logits_id, feats
model = OSNetReID(
num_ids=num_train_ids,
model_name=MODEL_NAME, pretrained=True
).to(DEVICE)
model
Successfully loaded imagenet pretrained weights from "/home/n03an/.cache/torch/checkpoints/osnet_x1_0_imagenet.pth"
** The following layers are discarded due to unmatched keys or layer size: ['classifier.weight', 'classifier.bias']
OSNetReID(
(backbone): OSNet(
(conv1): ConvLayer(
(conv): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(conv2): Sequential(
(0): OSBlock(
(conv1): Conv1x1(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(conv2a): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(conv2b): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(conv2c): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(conv2d): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(gate): ChannelGate(
(global_avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(64, 4, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU(inplace=True)
(fc2): Conv2d(4, 64, kernel_size=(1, 1), stride=(1, 1))
(gate_activation): Sigmoid()
)
(conv3): Conv1x1Linear(
(conv): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(downsample): Conv1x1Linear(
(conv): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): OSBlock(
(conv1): Conv1x1(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(conv2a): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(conv2b): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(conv2c): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(conv2d): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): LightConv3x3(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64, bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(gate): ChannelGate(
(global_avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(64, 4, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU(inplace=True)
(fc2): Conv2d(4, 64, kernel_size=(1, 1), stride=(1, 1))
(gate_activation): Sigmoid()
)
(conv3): Conv1x1Linear(
(conv): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): Sequential(
(0): Conv1x1(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
)
(conv3): Sequential(
(0): OSBlock(
(conv1): Conv1x1(
(conv): Conv2d(256, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(conv2a): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(conv2b): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(conv2c): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(conv2d): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(gate): ChannelGate(
(global_avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(96, 6, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU(inplace=True)
(fc2): Conv2d(6, 96, kernel_size=(1, 1), stride=(1, 1))
(gate_activation): Sigmoid()
)
(conv3): Conv1x1Linear(
(conv): Conv2d(96, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(downsample): Conv1x1Linear(
(conv): Conv2d(256, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): OSBlock(
(conv1): Conv1x1(
(conv): Conv2d(384, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(conv2a): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(conv2b): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(conv2c): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(conv2d): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): LightConv3x3(
(conv1): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=96, bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(gate): ChannelGate(
(global_avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(96, 6, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU(inplace=True)
(fc2): Conv2d(6, 96, kernel_size=(1, 1), stride=(1, 1))
(gate_activation): Sigmoid()
)
(conv3): Conv1x1Linear(
(conv): Conv2d(96, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(2): Sequential(
(0): Conv1x1(
(conv): Conv2d(384, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
)
(conv4): Sequential(
(0): OSBlock(
(conv1): Conv1x1(
(conv): Conv2d(384, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(conv2a): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(conv2b): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(conv2c): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(conv2d): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(gate): ChannelGate(
(global_avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(128, 8, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU(inplace=True)
(fc2): Conv2d(8, 128, kernel_size=(1, 1), stride=(1, 1))
(gate_activation): Sigmoid()
)
(conv3): Conv1x1Linear(
(conv): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(downsample): Conv1x1Linear(
(conv): Conv2d(384, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): OSBlock(
(conv1): Conv1x1(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(conv2a): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(conv2b): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(conv2c): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(conv2d): Sequential(
(0): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(1): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): LightConv3x3(
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(gate): ChannelGate(
(global_avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(128, 8, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU(inplace=True)
(fc2): Conv2d(8, 128, kernel_size=(1, 1), stride=(1, 1))
(gate_activation): Sigmoid()
)
(conv3): Conv1x1Linear(
(conv): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
(conv5): Conv1x1(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(global_avgpool): AdaptiveAvgPool2d(output_size=1)
(fc): Sequential(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(classifier): Linear(in_features=512, out_features=575, bias=True)
)
(bn): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(id_head): Linear(in_features=512, out_features=575, bias=True)
)
Batch hard triplet loss#
Goal: For each anchor, find the HARDEST positive and HARDEST negative in the batch
Hardest Positive (dist_ap): Same identity, FARTHEST away (max distance)
Hardest Negative (dist_an): Different identity, CLOSEST (min distance)
Loss pushes: dist_an > dist_ap + margin
read comments for more information
class BatchHardTripletLoss(nn.Module):
def __init__(self, margin=0.3):
super().__init__()
self.ranking_loss = nn.MarginRankingLoss(margin=margin)
def forward(self, embeddings, labels):
# Normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
# compute pairwise distance matrix (Euclidean distance)
dist = torch.cdist(embeddings, embeddings, p=2)
# For a batch of 64 (P=16, K=4):
# """
# img0 img1 img2 ... img63
# img0 [ 0 0.3 1.2 ... 0.8 ]
# img1 [ 0.3 0 0.9 ... 1.1 ]
# ...
# img63 [ 0.8 1.1 0.7 ... 0 ]
# """
# Build Positive/Negative Masks
labels = labels.view(-1, 1)
is_pos = labels.eq(labels.t())
is_neg = ~is_pos
diag = torch.eye(labels.size(0), dtype=torch.bool, device=labels.device)
is_pos = is_pos & ~diag
# find hardest positive and negative for each anchor
dist_ap = torch.where(is_pos, dist, torch.tensor(-1e9, device=dist.device)).max(dim=1)[0]
dist_an = torch.where(is_neg, dist, torch.tensor(1e9, device=dist.device)).min(dim=1)[0]
# filter invalid anchors
valid = (dist_ap > -1e8) & (dist_an < 1e8)
if valid.sum() == 0:
return torch.tensor(0.0, device=embeddings.device, requires_grad=True)
dist_ap = dist_ap[valid]
dist_an = dist_an[valid]
# loss = max(0, margin + dist_ap - dist_an)
# dist_an > dist_ap + margin = 0 (satisfied)
# dist_an < dist_ap + margin = positive (penalized)
y = torch.ones_like(dist_an)
return self.ranking_loss(dist_an, dist_ap, y)
CrossEntropyLoss combines LogSoftmax + Negative Log-Likelihood Loss in one step. It measures how well predicted class probabilities match the true labels. In our case ce_id_loss_fn(logits_id, pids), will accepts predicted and target vehicle id’s to calcuate the loss
# ReID losses
ce_id_loss_fn = nn.CrossEntropyLoss(label_smoothing=LABEL_SMOOTHING)
tri_loss_fn = BatchHardTripletLoss(margin=TRIPLET_MARGIN)
# Auxiliary losses
# ce_color_loss_fn = nn.CrossEntropyLoss()
# ce_type_loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=LR, weight_decay=WEIGHT_DECAY)
# was hitting LR to 0 at 43 epoch. Adding eta_min to prevent hitting zero
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max=EPOCHS,
eta_min=1e-6
)
Single Epoch training#
VeRi supports additional identity inputs such as color and type but they werent helping with the training and convergence
Input: Batch of images with labels (pid i.e. vehicleid, ~~color, type~~)
Model Forward Pass (logits_id, ~~logits_color, logits_type, feats~~)
2 Losses (weighted sum)
ID CrossEntropy (W_ID=1.0) Primary task — classify vehicle identity
Triplet Loss (W_TRI=1.0) Primary task — metric learning for retrieval
Backpropogation + Optimizer
def train_one_epoch(
model,
loader,
optimizer,
ce_id_loss_fn,
tri_loss_fn,
device="cuda",
w_id=1.0,
w_tri=1.0
):
model.train()
running = {
"loss": 0.0,
"id": 0.0,
"tri": 0.0,
"acc_id": 0.0,
"n": 0
}
pbar = tqdm(loader, desc="Train", leave=False)
for batch in pbar:
imgs, pids, camids, paths = batch
imgs = imgs.to(device, non_blocking=True)
pids = pids.to(device, non_blocking=True)
logits_id, feats = model(imgs)
loss_id = ce_id_loss_fn(logits_id, pids)
loss_tri = tri_loss_fn(feats, pids)
loss = w_id * loss_id + w_tri * loss_tri
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
acc_id = (logits_id.argmax(dim=1) == pids).float().mean().item()
bs = imgs.size(0)
running["loss"] += loss.item() * bs
running["id"] += loss_id.item() * bs
running["tri"] += loss_tri.item() * bs
running["acc_id"] += acc_id * bs
running["n"] += bs
pbar.set_postfix({
"loss": f"{running['loss']/running['n']:.4f}",
"id": f"{running['id']/running['n']:.3f}",
"tri": f"{running['tri']/running['n']:.3f}",
"acc": f"{running['acc_id']/running['n']:.3f}",
})
for k in ["loss", "id", "tri", "acc_id"]:
running[k] /= max(1, running["n"])
return running
Feature extractor for evaluation / retrieval#
Input: DataLoader (query or test)
Forward pass: get raw features [B, 512]
L2 normalize: unit sphere embeddings
Collect features, pids, camids, names
output: (feats_all, pids_all, camids_all, names_all)
@torch.no_grad()
def extract_features(model, loader, device, keep_on_gpu=False):
model.eval()
feats_all = []
pids_all = []
camids_all = []
names_all = []
for imgs, pids, camids, img_names in tqdm(loader, desc="Extract", leave=False):
imgs = imgs.to(device, non_blocking=True)
logits_id, feats = model(imgs)
feats = F.normalize(feats, p=2, dim=1)
# this will increse GPU memory usage but would be faster
# avoid GPU-cpu copy and we have around (1678 queries × 11579 gallery = ~19M operations)
feats_all.append(feats if keep_on_gpu else feats.cpu())
pids_all.extend([int(x) for x in pids])
camids_all.extend([int(x) for x in camids])
names_all.extend(list(img_names))
feats_all = torch.cat(feats_all, dim=0)
return feats_all, np.array(pids_all), np.array(camids_all), names_all
qf, _, _, qnames_from_loader = extract_features(model, query_loader, device=DEVICE)
print("Order match:", qnames_from_loader[:5] == query_names[:5])
print(qnames_from_loader[:5])
print(query_names[:5])
Order match: True
['0002_c002_00030600_0.jpg', '0002_c003_00084280_0.jpg', '0002_c004_00084250_0.jpg', '0002_c005_00084980_0.jpg', '0002_c006_00083605_0.jpg']
['0002_c002_00030600_0.jpg', '0002_c003_00084280_0.jpg', '0002_c004_00084250_0.jpg', '0002_c005_00084980_0.jpg', '0002_c006_00083605_0.jpg']
def compute_cosine_distmat(qf, gf):
# qf, gf are normalized
return (1.0 - torch.mm(qf, gf.t())).cpu().numpy()
Using mAP and CMC metrics for ReID evals#
Both metrics evaluate retrieval quality — how well your model ranks correct matches above incorrect ones (after removing junk)
CMC (Cumulative Match Characteristic)#
Focus on: “Did the correct match appear in the top-K results?”
e.g.: Vehicle 0042 from Camera 11
Ranked Gallery (after removing junk):
Rank 1: Vehicle 0099 ✗
Rank 2: Vehicle 0042 ✓ First correct match!
Rank 3: Vehicle 0055 ✗
Rank 4: Vehicle 0042 ✓ second correct
...
CMC vector: [0, 1, 1, 1, 1, ...]
↑ ↑
│ └─ Found at rank 2, stays 1 forever
└─── Not found at rank 1
Rank-1: % of queries where top result is correct
Rank-5: % of queries with correct result in top 5
Rank-10: % of queries with correct result in top 10
CMC only cares about the first correct match. It ignores whether you found 1 or 100 correct matches.
mAP (Mean Average Precision)#
Focus on: “How well are all correct matches ranked?
Query: Find vehicle 0042 (3 GT matches exist in gallery)
Ranked results:
Rank 1: 0042 ✓ → Precision = 1/1 = 1.000
Rank 2: 0099 ✗
Rank 3: 0042 ✓ → Precision = 2/3 = 0.667
Rank 4: 0055 ✗
Rank 5: 0042 ✓ → Precision = 3/5 = 0.600
calculate averate precision (AP)
AP = (1.000 + 0.667 + 0.600) / 3 = 0.756
calculate mean AP
mAP = mean([AP_q1, AP_q2, ..., AP_qN])
mAP will be our primary metric for ReID#
def eval_veri_protocol(distmat, query_names, gt_idx_map, jk_idx_map, max_rank=50, verbose=True):
num_q, num_g = distmat.shape
max_rank = min(max_rank, num_g)
all_cmc = []
all_ap = []
valid_q = 0
no_gt = 0
no_match = 0
for i, qname in enumerate(query_names):
gt_set = gt_idx_map.get(qname, set())
jk_set = jk_idx_map.get(qname, set())
if len(gt_set) == 0:
no_gt += 1
continue
order = np.argsort(distmat[i]) # ranked gallery indices (ascending distance)
# remove junk gallery indices
ranked = [gidx for gidx in order if gidx not in jk_set]
# binary relevance vector (1 if ranked gallery index is GT)
matches = np.array([1 if gidx in gt_set else 0 for gidx in ranked], dtype=np.int32)
if matches.sum() == 0:
no_match += 1
continue
# CMC
cmc = matches.cumsum()
cmc[cmc > 1] = 1
all_cmc.append(cmc[:max_rank])
# AP
valid_q += 1
num_rel = matches.sum()
tmp_cmc = matches.cumsum()
precisions = [tmp_cmc[k] / (k + 1.0) for k in range(len(matches)) if matches[k] == 1]
ap = np.sum(precisions) / num_rel
all_ap.append(ap)
if verbose:
print(f"[Eval Debug] total_q={num_q}, valid_q={valid_q}, no_gt={no_gt}, no_match={no_match}")
if valid_q == 0:
raise AssertionError(
"No valid queries found during evaluation using index protocol. "
"Check 0-based vs 1-based parsing in gt_index/jk_index files."
)
# Pad CMC arrays
padded = []
for c in all_cmc:
if len(c) < max_rank:
pad_val = c[-1] if len(c) > 0 else 0
c = np.pad(c, (0, max_rank - len(c)), mode="constant", constant_values=pad_val)
padded.append(c)
cmc = np.mean(np.asarray(padded, dtype=np.float32), axis=0)
mAP = float(np.mean(all_ap))
return cmc, mAP
Model Evaluation#
@torch.no_grad()
def evaluate_model(
model,
query_loader,
gallery_loader,
gt_idx_map,
jk_idx_map,
device,
max_rank=20,
verbose=True
):
# Extract features
qf, _, _, qnames = extract_features(model, query_loader, device=device, keep_on_gpu=True)
gf, _, _, gnames = extract_features(model, gallery_loader, device=device, keep_on_gpu=True)
# Compute distance matrix (cosine distance since features are L2-normalized)
distmat = (1.0 - torch.mm(qf, gf.t())).cpu().numpy()
# Run VeRi evaluation protocol
cmc, mAP = eval_veri_protocol(
distmat=distmat,
query_names=qnames,
gt_idx_map=gt_idx_map,
jk_idx_map=jk_idx_map,
max_rank=max_rank,
verbose=verbose
)
return {
"standard": {
"mAP": mAP,
"Rank-1": float(cmc[0]),
"Rank-5": float(cmc[4]) if len(cmc) > 4 else None,
"Rank-10": float(cmc[9]) if len(cmc) > 9 else None,
},
"features": {
"qf": qf,
"qnames": qnames,
"gf": gf,
"gnames": gnames,
}
}
Training Loop#
import time
from datetime import datetime
from pathlib import Path
import torch
best_map = -1.0
best_epoch = -1
no_improve_evals = 0
save_dir = Path("../models/checkpoints_osnet_veri")
save_dir.mkdir(parents=True, exist_ok=True)
train_start_dt = datetime.now()
train_start_perf = time.perf_counter()
print("=== Training Config ===")
print(f"Backbone : {MODEL_NAME}")
print(f"Triplet weight : {W_TRI}")
print(f"Batch size : {BATCH_SIZE} (P={P}, K={K})")
print(f"Image size : {IMG_H}x{IMG_W}")
print(f"LR : {LR}")
print(f"Epochs : {EPOCHS}")
print(f"Eval every : {EVAL_EVERY}")
print("=======================")
print(f"Training started at: {train_start_dt.strftime('%Y-%m-%d %H:%M:%S')}")
for epoch in range(1, EPOCHS + 1):
epoch_start_dt = datetime.now()
epoch_start_perf = time.perf_counter()
stats = train_one_epoch(
model, train_loader, optimizer,
ce_id_loss_fn, tri_loss_fn,
device=DEVICE,
w_id=W_ID, w_tri=W_TRI
)
scheduler.step()
epoch_elapsed = time.perf_counter() - epoch_start_perf
print(
f"🔘 Epoch {epoch:03d} | start={epoch_start_dt.strftime('%H:%M:%S')} | "
f"epoch_time={epoch_elapsed:.1f}s ({epoch_elapsed/60:.2f}m) \n"
f"===> loss={stats['loss']:.4f} vehicleid_ce={stats['id']:.3f} tri={stats['tri']:.3f} "
f"acc_vehicleid={stats['acc_id']:.3f} lr={optimizer.param_groups[0]['lr']:.6f}"
)
if epoch % EVAL_EVERY == 0 or epoch == EPOCHS:
eval_start = time.perf_counter()
results = evaluate_model(
model=model,
query_loader=query_loader,
gallery_loader=gallery_loader,
gt_idx_map=gt_idx_map,
jk_idx_map=jk_idx_map,
device=DEVICE,
max_rank=20,
verbose=False
)
eval_elapsed = time.perf_counter() - eval_start
std = results["standard"]
curr_map = std["mAP"]
print(
f"⭕ [Eval] mAP={curr_map:.4f} "
f"R1={std['Rank-1']:.4f} R5={std['Rank-5']:.4f} R10={std['Rank-10']:.4f} "
f"| eval_time={eval_elapsed:.1f}s"
)
# Save last every eval
torch.save(
{"model": model.state_dict(), "epoch": epoch, "best_map": best_map},
save_dir / "last.pth"
)
# Best model tracking + patience
if curr_map > (best_map + EARLY_STOP_MIN_DELTA):
best_map = curr_map
best_epoch = epoch
no_improve_evals = 0
torch.save(
{"model": model.state_dict(), "epoch": epoch, "best_map": best_map},
save_dir / "best.pth"
)
print(f"Saved best model (mAP={best_map:.4f}) at epoch {best_epoch}")
else:
no_improve_evals += 1
print(f" ⏸ No significant mAP improvement | patience {no_improve_evals}/{EARLY_STOP_PATIENCE_EVALS}")
# Early stop condition
if no_improve_evals >= EARLY_STOP_PATIENCE_EVALS:
print(f"\nEarly stopping triggered at epoch {epoch}. Best mAP={best_map:.4f} (epoch {best_epoch})")
break
train_end_dt = datetime.now()
total_elapsed = time.perf_counter() - train_start_perf
print("\nTraining completed.")
print(f"Started at : {train_start_dt.strftime('%Y-%m-%d %H:%M:%S')}")
print(f"Ended at : {train_end_dt.strftime('%Y-%m-%d %H:%M:%S')}")
print(f"Total time : {total_elapsed:.1f}s ({total_elapsed/60:.2f}m / {total_elapsed/3600:.2f}h)")
print(f"Best mAP : {best_map:.4f} at epoch {best_epoch}")
=== Training Config ===
Backbone : osnet_x1_0
Triplet weight : 1.0
Batch size : 64 (P=16, K=4)
Image size : 256x256
LR : 0.0003
Epochs : 100
Eval every : 5
=======================
Training started at: 2026-02-23 11:00:41
🔘 Epoch 001 | start=11:00:41 | epoch_time=49.8s (0.83m)
===> loss=4.6344 vehicleid_ce=4.312 tri=0.322 acc_vehicleid=0.292 lr=0.000300
🔘 Epoch 002 | start=11:01:30 | epoch_time=49.5s (0.82m)
===> loss=2.6813 vehicleid_ce=2.410 tri=0.272 acc_vehicleid=0.681 lr=0.000300
🔘 Epoch 003 | start=11:02:20 | epoch_time=49.2s (0.82m)
===> loss=1.9002 vehicleid_ce=1.649 tri=0.251 acc_vehicleid=0.865 lr=0.000299
🔘 Epoch 004 | start=11:03:09 | epoch_time=48.9s (0.82m)
===> loss=1.6375 vehicleid_ce=1.408 tri=0.229 acc_vehicleid=0.928 lr=0.000299
🔘 Epoch 005 | start=11:03:58 | epoch_time=48.9s (0.82m)
===> loss=1.4965 vehicleid_ce=1.300 tri=0.196 acc_vehicleid=0.957 lr=0.000298
⭕ [Eval] mAP=0.5637 R1=0.8766 R5=0.9422 R10=0.9684 | eval_time=8.4s
Saved best model (mAP=0.5637) at epoch 5
🔘 Epoch 006 | start=11:04:55 | epoch_time=48.6s (0.81m)
===> loss=1.4203 vehicleid_ce=1.251 tri=0.169 acc_vehicleid=0.967 lr=0.000297
🔘 Epoch 007 | start=11:05:44 | epoch_time=48.3s (0.81m)
===> loss=1.3670 vehicleid_ce=1.222 tri=0.145 acc_vehicleid=0.974 lr=0.000296
🔘 Epoch 008 | start=11:06:32 | epoch_time=48.2s (0.80m)
===> loss=1.3197 vehicleid_ce=1.196 tri=0.124 acc_vehicleid=0.978 lr=0.000295
🔘 Epoch 009 | start=11:07:21 | epoch_time=48.0s (0.80m)
===> loss=1.2849 vehicleid_ce=1.175 tri=0.110 acc_vehicleid=0.984 lr=0.000294
🔘 Epoch 010 | start=11:08:09 | epoch_time=48.2s (0.80m)
===> loss=1.2583 vehicleid_ce=1.161 tri=0.098 acc_vehicleid=0.986 lr=0.000293
⭕ [Eval] mAP=0.6002 R1=0.8772 R5=0.9410 R10=0.9619 | eval_time=8.5s
Saved best model (mAP=0.6002) at epoch 10
🔘 Epoch 011 | start=11:09:05 | epoch_time=48.5s (0.81m)
===> loss=1.2409 vehicleid_ce=1.151 tri=0.090 acc_vehicleid=0.986 lr=0.000291
🔘 Epoch 012 | start=11:09:54 | epoch_time=49.0s (0.82m)
===> loss=1.2233 vehicleid_ce=1.140 tri=0.084 acc_vehicleid=0.988 lr=0.000290
🔘 Epoch 013 | start=11:10:43 | epoch_time=49.8s (0.83m)
===> loss=1.2059 vehicleid_ce=1.131 tri=0.075 acc_vehicleid=0.990 lr=0.000288
🔘 Epoch 014 | start=11:11:32 | epoch_time=49.4s (0.82m)
===> loss=1.1942 vehicleid_ce=1.124 tri=0.070 acc_vehicleid=0.990 lr=0.000286
🔘 Epoch 015 | start=11:12:22 | epoch_time=48.8s (0.81m)
===> loss=1.1782 vehicleid_ce=1.112 tri=0.067 acc_vehicleid=0.993 lr=0.000284
⭕ [Eval] mAP=0.6115 R1=0.8802 R5=0.9434 R10=0.9631 | eval_time=8.5s
Saved best model (mAP=0.6115) at epoch 15
🔘 Epoch 016 | start=11:13:19 | epoch_time=48.7s (0.81m)
===> loss=1.1754 vehicleid_ce=1.111 tri=0.064 acc_vehicleid=0.992 lr=0.000282
🔘 Epoch 017 | start=11:14:08 | epoch_time=49.1s (0.82m)
===> loss=1.1600 vehicleid_ce=1.102 tri=0.058 acc_vehicleid=0.993 lr=0.000279
🔘 Epoch 018 | start=11:14:57 | epoch_time=48.8s (0.81m)
===> loss=1.1533 vehicleid_ce=1.099 tri=0.055 acc_vehicleid=0.994 lr=0.000277
🔘 Epoch 019 | start=11:15:46 | epoch_time=48.9s (0.82m)
===> loss=1.1469 vehicleid_ce=1.095 tri=0.052 acc_vehicleid=0.994 lr=0.000274
🔘 Epoch 020 | start=11:16:35 | epoch_time=48.8s (0.81m)
===> loss=1.1382 vehicleid_ce=1.088 tri=0.050 acc_vehicleid=0.995 lr=0.000271
⭕ [Eval] mAP=0.6223 R1=0.8856 R5=0.9428 R10=0.9648 | eval_time=8.5s
Saved best model (mAP=0.6223) at epoch 20
🔘 Epoch 021 | start=11:17:32 | epoch_time=48.1s (0.80m)
===> loss=1.1298 vehicleid_ce=1.084 tri=0.046 acc_vehicleid=0.995 lr=0.000269
🔘 Epoch 022 | start=11:18:20 | epoch_time=48.8s (0.81m)
===> loss=1.1274 vehicleid_ce=1.082 tri=0.045 acc_vehicleid=0.995 lr=0.000266
🔘 Epoch 023 | start=11:19:09 | epoch_time=49.4s (0.82m)
===> loss=1.1226 vehicleid_ce=1.079 tri=0.043 acc_vehicleid=0.995 lr=0.000263
🔘 Epoch 024 | start=11:19:58 | epoch_time=49.7s (0.83m)
===> loss=1.1166 vehicleid_ce=1.076 tri=0.041 acc_vehicleid=0.995 lr=0.000259
🔘 Epoch 025 | start=11:20:48 | epoch_time=49.3s (0.82m)
===> loss=1.1133 vehicleid_ce=1.073 tri=0.041 acc_vehicleid=0.996 lr=0.000256
⭕ [Eval] mAP=0.6399 R1=0.9029 R5=0.9553 R10=0.9714 | eval_time=8.6s
Saved best model (mAP=0.6399) at epoch 25
🔘 Epoch 026 | start=11:21:46 | epoch_time=48.2s (0.80m)
===> loss=1.1040 vehicleid_ce=1.067 tri=0.037 acc_vehicleid=0.997 lr=0.000253
🔘 Epoch 027 | start=11:22:34 | epoch_time=48.0s (0.80m)
===> loss=1.1014 vehicleid_ce=1.066 tri=0.036 acc_vehicleid=0.997 lr=0.000249
🔘 Epoch 028 | start=11:23:22 | epoch_time=48.3s (0.81m)
===> loss=1.1016 vehicleid_ce=1.065 tri=0.036 acc_vehicleid=0.997 lr=0.000246
🔘 Epoch 029 | start=11:24:11 | epoch_time=47.9s (0.80m)
===> loss=1.0972 vehicleid_ce=1.064 tri=0.034 acc_vehicleid=0.996 lr=0.000242
🔘 Epoch 030 | start=11:24:59 | epoch_time=48.7s (0.81m)
===> loss=1.0927 vehicleid_ce=1.059 tri=0.034 acc_vehicleid=0.997 lr=0.000238
⭕ [Eval] mAP=0.6499 R1=0.9041 R5=0.9541 R10=0.9702 | eval_time=8.5s
Saved best model (mAP=0.6499) at epoch 30
🔘 Epoch 031 | start=11:25:56 | epoch_time=48.9s (0.82m)
===> loss=1.0851 vehicleid_ce=1.055 tri=0.030 acc_vehicleid=0.997 lr=0.000235
🔘 Epoch 032 | start=11:26:45 | epoch_time=48.3s (0.81m)
===> loss=1.0830 vehicleid_ce=1.053 tri=0.030 acc_vehicleid=0.997 lr=0.000231
🔘 Epoch 033 | start=11:27:33 | epoch_time=49.2s (0.82m)
===> loss=1.0796 vehicleid_ce=1.052 tri=0.028 acc_vehicleid=0.997 lr=0.000227
🔘 Epoch 034 | start=11:28:22 | epoch_time=49.2s (0.82m)
===> loss=1.0784 vehicleid_ce=1.049 tri=0.029 acc_vehicleid=0.997 lr=0.000223
🔘 Epoch 035 | start=11:29:12 | epoch_time=49.2s (0.82m)
===> loss=1.0760 vehicleid_ce=1.049 tri=0.027 acc_vehicleid=0.998 lr=0.000218
⭕ [Eval] mAP=0.6530 R1=0.8975 R5=0.9535 R10=0.9690 | eval_time=8.5s
Saved best model (mAP=0.6530) at epoch 35
🔘 Epoch 036 | start=11:30:09 | epoch_time=49.6s (0.83m)
===> loss=1.0716 vehicleid_ce=1.046 tri=0.026 acc_vehicleid=0.998 lr=0.000214
🔘 Epoch 037 | start=11:30:59 | epoch_time=48.3s (0.80m)
===> loss=1.0713 vehicleid_ce=1.046 tri=0.026 acc_vehicleid=0.998 lr=0.000210
🔘 Epoch 038 | start=11:31:47 | epoch_time=48.5s (0.81m)
===> loss=1.0660 vehicleid_ce=1.042 tri=0.024 acc_vehicleid=0.998 lr=0.000206
🔘 Epoch 039 | start=11:32:36 | epoch_time=48.4s (0.81m)
===> loss=1.0643 vehicleid_ce=1.040 tri=0.024 acc_vehicleid=0.998 lr=0.000201
🔘 Epoch 040 | start=11:33:24 | epoch_time=48.3s (0.80m)
===> loss=1.0615 vehicleid_ce=1.039 tri=0.022 acc_vehicleid=0.998 lr=0.000197
⭕ [Eval] mAP=0.6623 R1=0.9124 R5=0.9523 R10=0.9720 | eval_time=8.4s
Saved best model (mAP=0.6623) at epoch 40
🔘 Epoch 041 | start=11:34:21 | epoch_time=48.6s (0.81m)
===> loss=1.0585 vehicleid_ce=1.037 tri=0.021 acc_vehicleid=0.998 lr=0.000192
🔘 Epoch 042 | start=11:35:10 | epoch_time=48.8s (0.81m)
===> loss=1.0579 vehicleid_ce=1.035 tri=0.023 acc_vehicleid=0.999 lr=0.000188
🔘 Epoch 043 | start=11:35:58 | epoch_time=48.5s (0.81m)
===> loss=1.0558 vehicleid_ce=1.035 tri=0.021 acc_vehicleid=0.998 lr=0.000183
🔘 Epoch 044 | start=11:36:47 | epoch_time=49.4s (0.82m)
===> loss=1.0525 vehicleid_ce=1.032 tri=0.020 acc_vehicleid=0.999 lr=0.000179
🔘 Epoch 045 | start=11:37:36 | epoch_time=49.0s (0.82m)
===> loss=1.0533 vehicleid_ce=1.032 tri=0.021 acc_vehicleid=0.998 lr=0.000174
⭕ [Eval] mAP=0.6624 R1=0.9094 R5=0.9625 R10=0.9738 | eval_time=8.6s
⏸ No significant mAP improvement | patience 1/3
🔘 Epoch 046 | start=11:38:34 | epoch_time=50.4s (0.84m)
===> loss=1.0495 vehicleid_ce=1.030 tri=0.019 acc_vehicleid=0.999 lr=0.000169
🔘 Epoch 047 | start=11:39:24 | epoch_time=49.5s (0.83m)
===> loss=1.0475 vehicleid_ce=1.028 tri=0.019 acc_vehicleid=0.999 lr=0.000165
🔘 Epoch 048 | start=11:40:14 | epoch_time=48.2s (0.80m)
===> loss=1.0439 vehicleid_ce=1.027 tri=0.017 acc_vehicleid=0.999 lr=0.000160
🔘 Epoch 049 | start=11:41:02 | epoch_time=48.3s (0.80m)
===> loss=1.0435 vehicleid_ce=1.025 tri=0.018 acc_vehicleid=0.999 lr=0.000155
🔘 Epoch 050 | start=11:41:50 | epoch_time=48.8s (0.81m)
===> loss=1.0423 vehicleid_ce=1.025 tri=0.018 acc_vehicleid=0.999 lr=0.000150
⭕ [Eval] mAP=0.6702 R1=0.9148 R5=0.9577 R10=0.9702 | eval_time=8.4s
Saved best model (mAP=0.6702) at epoch 50
🔘 Epoch 051 | start=11:42:47 | epoch_time=47.9s (0.80m)
===> loss=1.0382 vehicleid_ce=1.023 tri=0.016 acc_vehicleid=0.999 lr=0.000146
🔘 Epoch 052 | start=11:43:35 | epoch_time=47.6s (0.79m)
===> loss=1.0376 vehicleid_ce=1.022 tri=0.016 acc_vehicleid=0.999 lr=0.000141
🔘 Epoch 053 | start=11:44:23 | epoch_time=47.9s (0.80m)
===> loss=1.0378 vehicleid_ce=1.020 tri=0.017 acc_vehicleid=0.999 lr=0.000136
🔘 Epoch 054 | start=11:45:11 | epoch_time=49.2s (0.82m)
===> loss=1.0357 vehicleid_ce=1.021 tri=0.015 acc_vehicleid=0.999 lr=0.000132
🔘 Epoch 055 | start=11:46:00 | epoch_time=49.2s (0.82m)
===> loss=1.0345 vehicleid_ce=1.019 tri=0.016 acc_vehicleid=0.999 lr=0.000127
⭕ [Eval] mAP=0.6743 R1=0.9160 R5=0.9625 R10=0.9732 | eval_time=8.5s
Saved best model (mAP=0.6743) at epoch 55
🔘 Epoch 056 | start=11:46:58 | epoch_time=48.6s (0.81m)
===> loss=1.0322 vehicleid_ce=1.018 tri=0.014 acc_vehicleid=0.999 lr=0.000122
🔘 Epoch 057 | start=11:47:46 | epoch_time=48.9s (0.81m)
===> loss=1.0293 vehicleid_ce=1.016 tri=0.013 acc_vehicleid=0.999 lr=0.000118
🔘 Epoch 058 | start=11:48:35 | epoch_time=48.8s (0.81m)
===> loss=1.0308 vehicleid_ce=1.017 tri=0.014 acc_vehicleid=0.999 lr=0.000113
🔘 Epoch 059 | start=11:49:24 | epoch_time=49.0s (0.82m)
===> loss=1.0300 vehicleid_ce=1.015 tri=0.015 acc_vehicleid=0.999 lr=0.000109
🔘 Epoch 060 | start=11:50:13 | epoch_time=47.6s (0.79m)
===> loss=1.0270 vehicleid_ce=1.014 tri=0.013 acc_vehicleid=0.999 lr=0.000104
⭕ [Eval] mAP=0.6819 R1=0.9118 R5=0.9613 R10=0.9738 | eval_time=8.4s
Saved best model (mAP=0.6819) at epoch 60
🔘 Epoch 061 | start=11:51:09 | epoch_time=48.0s (0.80m)
===> loss=1.0248 vehicleid_ce=1.013 tri=0.012 acc_vehicleid=0.999 lr=0.000100
🔘 Epoch 062 | start=11:51:57 | epoch_time=47.8s (0.80m)
===> loss=1.0227 vehicleid_ce=1.011 tri=0.011 acc_vehicleid=0.999 lr=0.000095
🔘 Epoch 063 | start=11:52:45 | epoch_time=48.6s (0.81m)
===> loss=1.0229 vehicleid_ce=1.011 tri=0.012 acc_vehicleid=0.999 lr=0.000091
🔘 Epoch 064 | start=11:53:33 | epoch_time=47.9s (0.80m)
===> loss=1.0207 vehicleid_ce=1.010 tri=0.011 acc_vehicleid=0.999 lr=0.000087
🔘 Epoch 065 | start=11:54:21 | epoch_time=48.9s (0.82m)
===> loss=1.0209 vehicleid_ce=1.009 tri=0.012 acc_vehicleid=0.999 lr=0.000083
⭕ [Eval] mAP=0.6851 R1=0.9148 R5=0.9619 R10=0.9756 | eval_time=8.5s
Saved best model (mAP=0.6851) at epoch 65
🔘 Epoch 066 | start=11:55:19 | epoch_time=48.8s (0.81m)
===> loss=1.0205 vehicleid_ce=1.009 tri=0.012 acc_vehicleid=0.999 lr=0.000078
🔘 Epoch 067 | start=11:56:08 | epoch_time=48.3s (0.81m)
===> loss=1.0184 vehicleid_ce=1.008 tri=0.011 acc_vehicleid=1.000 lr=0.000074
🔘 Epoch 068 | start=11:56:56 | epoch_time=48.6s (0.81m)
===> loss=1.0166 vehicleid_ce=1.007 tri=0.010 acc_vehicleid=0.999 lr=0.000070
🔘 Epoch 069 | start=11:57:45 | epoch_time=48.5s (0.81m)
===> loss=1.0152 vehicleid_ce=1.006 tri=0.009 acc_vehicleid=1.000 lr=0.000066
🔘 Epoch 070 | start=11:58:33 | epoch_time=48.1s (0.80m)
===> loss=1.0166 vehicleid_ce=1.006 tri=0.010 acc_vehicleid=0.999 lr=0.000063
⭕ [Eval] mAP=0.6889 R1=0.9166 R5=0.9660 R10=0.9732 | eval_time=8.4s
Saved best model (mAP=0.6889) at epoch 70
🔘 Epoch 071 | start=11:59:30 | epoch_time=47.7s (0.80m)
===> loss=1.0157 vehicleid_ce=1.005 tri=0.011 acc_vehicleid=1.000 lr=0.000059
🔘 Epoch 072 | start=12:00:17 | epoch_time=47.7s (0.80m)
===> loss=1.0147 vehicleid_ce=1.005 tri=0.010 acc_vehicleid=0.999 lr=0.000055
🔘 Epoch 073 | start=12:01:05 | epoch_time=47.7s (0.80m)
===> loss=1.0113 vehicleid_ce=1.003 tri=0.008 acc_vehicleid=1.000 lr=0.000052
🔘 Epoch 074 | start=12:01:53 | epoch_time=47.6s (0.79m)
===> loss=1.0133 vehicleid_ce=1.003 tri=0.010 acc_vehicleid=1.000 lr=0.000048
🔘 Epoch 075 | start=12:02:40 | epoch_time=47.5s (0.79m)
===> loss=1.0110 vehicleid_ce=1.002 tri=0.009 acc_vehicleid=1.000 lr=0.000045
⭕ [Eval] mAP=0.6905 R1=0.9243 R5=0.9619 R10=0.9750 | eval_time=8.1s
Saved best model (mAP=0.6905) at epoch 75
🔘 Epoch 076 | start=12:03:36 | epoch_time=47.8s (0.80m)
===> loss=1.0111 vehicleid_ce=1.002 tri=0.009 acc_vehicleid=1.000 lr=0.000042
🔘 Epoch 077 | start=12:04:24 | epoch_time=47.7s (0.79m)
===> loss=1.0109 vehicleid_ce=1.002 tri=0.009 acc_vehicleid=1.000 lr=0.000038
🔘 Epoch 078 | start=12:05:12 | epoch_time=47.9s (0.80m)
===> loss=1.0101 vehicleid_ce=1.001 tri=0.009 acc_vehicleid=1.000 lr=0.000035
🔘 Epoch 079 | start=12:06:00 | epoch_time=48.1s (0.80m)
===> loss=1.0080 vehicleid_ce=1.000 tri=0.008 acc_vehicleid=1.000 lr=0.000032
🔘 Epoch 080 | start=12:06:48 | epoch_time=48.1s (0.80m)
===> loss=1.0082 vehicleid_ce=1.000 tri=0.008 acc_vehicleid=1.000 lr=0.000030
⭕ [Eval] mAP=0.6955 R1=0.9255 R5=0.9625 R10=0.9744 | eval_time=8.1s
Saved best model (mAP=0.6955) at epoch 80
🔘 Epoch 081 | start=12:07:44 | epoch_time=47.9s (0.80m)
===> loss=1.0080 vehicleid_ce=1.000 tri=0.008 acc_vehicleid=1.000 lr=0.000027
🔘 Epoch 082 | start=12:08:32 | epoch_time=48.0s (0.80m)
===> loss=1.0067 vehicleid_ce=0.999 tri=0.007 acc_vehicleid=1.000 lr=0.000024
🔘 Epoch 083 | start=12:09:20 | epoch_time=47.4s (0.79m)
===> loss=1.0075 vehicleid_ce=0.999 tri=0.008 acc_vehicleid=1.000 lr=0.000022
🔘 Epoch 084 | start=12:10:07 | epoch_time=47.1s (0.79m)
===> loss=1.0066 vehicleid_ce=0.999 tri=0.007 acc_vehicleid=1.000 lr=0.000019
🔘 Epoch 085 | start=12:10:54 | epoch_time=47.9s (0.80m)
===> loss=1.0064 vehicleid_ce=0.999 tri=0.008 acc_vehicleid=1.000 lr=0.000017
⭕ [Eval] mAP=0.6962 R1=0.9219 R5=0.9636 R10=0.9762 | eval_time=8.1s
⏸ No significant mAP improvement | patience 1/3
🔘 Epoch 086 | start=12:11:50 | epoch_time=47.6s (0.79m)
===> loss=1.0063 vehicleid_ce=0.998 tri=0.008 acc_vehicleid=1.000 lr=0.000015
🔘 Epoch 087 | start=12:12:38 | epoch_time=48.2s (0.80m)
===> loss=1.0056 vehicleid_ce=0.998 tri=0.008 acc_vehicleid=1.000 lr=0.000013
🔘 Epoch 088 | start=12:13:26 | epoch_time=47.9s (0.80m)
===> loss=1.0055 vehicleid_ce=0.998 tri=0.007 acc_vehicleid=1.000 lr=0.000011
🔘 Epoch 089 | start=12:14:14 | epoch_time=47.8s (0.80m)
===> loss=1.0053 vehicleid_ce=0.997 tri=0.008 acc_vehicleid=1.000 lr=0.000010
🔘 Epoch 090 | start=12:15:02 | epoch_time=48.0s (0.80m)
===> loss=1.0041 vehicleid_ce=0.997 tri=0.007 acc_vehicleid=1.000 lr=0.000008
⭕ [Eval] mAP=0.6981 R1=0.9225 R5=0.9666 R10=0.9774 | eval_time=8.1s
Saved best model (mAP=0.6981) at epoch 90
🔘 Epoch 091 | start=12:15:58 | epoch_time=48.3s (0.80m)
===> loss=1.0047 vehicleid_ce=0.998 tri=0.007 acc_vehicleid=1.000 lr=0.000007
🔘 Epoch 092 | start=12:16:46 | epoch_time=48.4s (0.81m)
===> loss=1.0050 vehicleid_ce=0.997 tri=0.008 acc_vehicleid=1.000 lr=0.000006
🔘 Epoch 093 | start=12:17:35 | epoch_time=48.3s (0.80m)
===> loss=1.0055 vehicleid_ce=0.998 tri=0.008 acc_vehicleid=1.000 lr=0.000005
🔘 Epoch 094 | start=12:18:23 | epoch_time=48.8s (0.81m)
===> loss=1.0040 vehicleid_ce=0.997 tri=0.007 acc_vehicleid=1.000 lr=0.000004
🔘 Epoch 095 | start=12:19:12 | epoch_time=47.2s (0.79m)
===> loss=1.0039 vehicleid_ce=0.997 tri=0.007 acc_vehicleid=1.000 lr=0.000003
⭕ [Eval] mAP=0.6977 R1=0.9249 R5=0.9660 R10=0.9774 | eval_time=8.1s
⏸ No significant mAP improvement | patience 1/3
🔘 Epoch 096 | start=12:20:07 | epoch_time=48.2s (0.80m)
===> loss=1.0042 vehicleid_ce=0.997 tri=0.007 acc_vehicleid=1.000 lr=0.000002
🔘 Epoch 097 | start=12:20:55 | epoch_time=48.4s (0.81m)
===> loss=1.0042 vehicleid_ce=0.997 tri=0.007 acc_vehicleid=1.000 lr=0.000002
🔘 Epoch 098 | start=12:21:44 | epoch_time=47.5s (0.79m)
===> loss=1.0037 vehicleid_ce=0.996 tri=0.007 acc_vehicleid=1.000 lr=0.000001
🔘 Epoch 099 | start=12:22:31 | epoch_time=47.0s (0.78m)
===> loss=1.0032 vehicleid_ce=0.997 tri=0.006 acc_vehicleid=1.000 lr=0.000001
🔘 Epoch 100 | start=12:23:18 | epoch_time=48.3s (0.80m)
===> loss=1.0043 vehicleid_ce=0.997 tri=0.007 acc_vehicleid=1.000 lr=0.000001
⭕ [Eval] mAP=0.6982 R1=0.9267 R5=0.9666 R10=0.9756 | eval_time=8.1s
⏸ No significant mAP improvement | patience 2/3
Training completed.
Started at : 2026-02-23 11:00:41
Ended at : 2026-02-23 12:24:15
Total time : 5014.1s (83.57m / 1.39h)
Best mAP : 0.6981 at epoch 90
since I am saving checkpoints with model prefix, will need to replace with backbone prefix as the model expects
ckpt = torch.load("../models/checkpoints_osnet_veri/best_v4.pth", map_location=DEVICE)
# Check what format the checkpoint is in
state_dict = ckpt["model"] if "model" in ckpt else ckpt
# Remap keys: model.* -> backbone.*
new_state_dict = {}
for k, v in state_dict.items():
if k.startswith("model."):
new_key = k.replace("model.", "backbone.", 1)
new_state_dict[new_key] = v
else:
new_state_dict[k] = v
# Load with strict=False to skip missing heads (bn, id_head)
model.load_state_dict(new_state_dict, strict=False)
model.eval()
print("Loaded best checkpoint")
print("Best epoch:", ckpt.get("epoch"))
print("Best mAP:", ckpt.get("best_map"))
Loaded best checkpoint
Best epoch: 90
Best mAP: 0.6981044452756111
qf, _, _, qnames = extract_features(model, query_loader, device=DEVICE)
gf, _, _, gnames = extract_features(model, gallery_loader, device=DEVICE)
# Pick fixed queries you care about
VIS_QUERY_IDXS = [0, 50, 111, 1399, 150, 200, 240, 300, 340, 400, 450, 500]
for qidx in VIS_QUERY_IDXS:
visualize_topk_side_by_side(
qf=qf,
qnames=qnames,
gf=gf,
gnames=gnames,
gt_idx_map=gt_idx_map,
jk_idx_map=jk_idx_map,
image_query_dir=IMAGE_QUERY_DIR,
image_test_dir=IMAGE_TEST_DIR,
query_idx=qidx,
topk=9,
gallery_cols=3,
show_junk=False,
fig_width=22,
row_height=4.0,
query_title_fontsize=16,
item_title_fontsize=16,
show_filenames=True,
show_score=True,
score_mode="similarity"
)












watch -n 1 'echo "GPU NAME UTIL % MEM % USED / TOTAL TEMP"; \
echo "---------------------------------------------------------------"; \
nvidia-smi --query-gpu=name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu \
--format=csv,noheader,nounits | awk -F ", " "{printf \"%-18s %-8s %-8s %-17s %-5s\n\", \$1, \$2\"%\", \$3\"%\", \$4\"MB/\"\$5\"MB\", \$6\"C\"}"'
